


Работа digital-специалиста сильно завязана на анализ трафика, и в будущем будет все больше и плотнее связываться с аналитикой. В рунете есть две самые популярные бесплатные системы веб-аналитики — Google Analytics и Яндекс.Метрика. Большинство аналитиков считают продукт от Google более продвинутым и функциональным. Но есть направления, где Яндекс опередил извечного конкурента и дал пользователям очень мощный и, на мой взгляд, наверное, самый пока недооцененный инструмент — выгрузку «сырых» или исходных данных по посещаемости вашего сайта в виде логов.
Выгрузка логов Logs API доступна с 18 ноября 2016 года. Более подробно о технических моментах вы можете прочитать в официальной документации Яндекса.
По настоящему всю мощь выгруженных логов вы можете оценить, начав проводить глубокий многофакторный анализ, в том числе с использованием техник машинного обучения, но пока оставим эту тему для следующих статей.
Сегодня мы поговорим о том, как создавать запросы к Logs API и выгружать сырые данные из Метрики с помощью скрипта на Python. Эта моя статья также, как и в предыдущие, нацелены на широкий круг читателей: от новичка до эксперта.
Практическое применение логов
Цель данной статьи — в первую очередь дать инструмент, которым мог бы воспользоваться даже человек, далекий от технических разработок для выгрузки исходных логов Метрики. Работа непосредственно с «сырыми» данными выходит за границы этого материала, но все же важно обозначить задачи, которые можно решать с их помощью.
Вот направления работы, которые рекомендует Яндекс для работы с логами:
- сложные воронки продаж;
- собственные модели атрибуции;
- объединение данных из разных источников;
- контроль над расхождениями в статистике.
Вы также сможете:
- проводить факторный анализ конверсий и прочих показателей;
- более глубоко исследовать метрики и зависимости;
- строить визуализации, недоступные в стандартных отчетах Яндекс.Метрики;
- использовать техники машинного обучения для построения моделей и проверки гипотез на «боевых» данных;
- автоматизировать рутинные типовые аналитические задач, что актуально для работы на потоке.
Если у вас есть что добавить в эти списки, обязательно напишите об этом в комментариях к статье.
Реализация скрипта
Скрипт реализован в текстово-диалоговом интерфейсе — в виде примитивного чат-бота, подробно механику разберем далее в статье. Такой формат позволяет достаточно просто взаимодействовать с API Яндекс.Метрики даже специалистам с минимальной технической подготовкой.
Общая схема работа API Метрики
Перед тем как мы начнем, очень важно понять общую схему работы API Метрики: создание запросов на сервере, проверка статуса и загрузка данных после того. Для лучшего понимания проиллюстрируем взаимодействие с серверами Метрики схематично на рисунке:
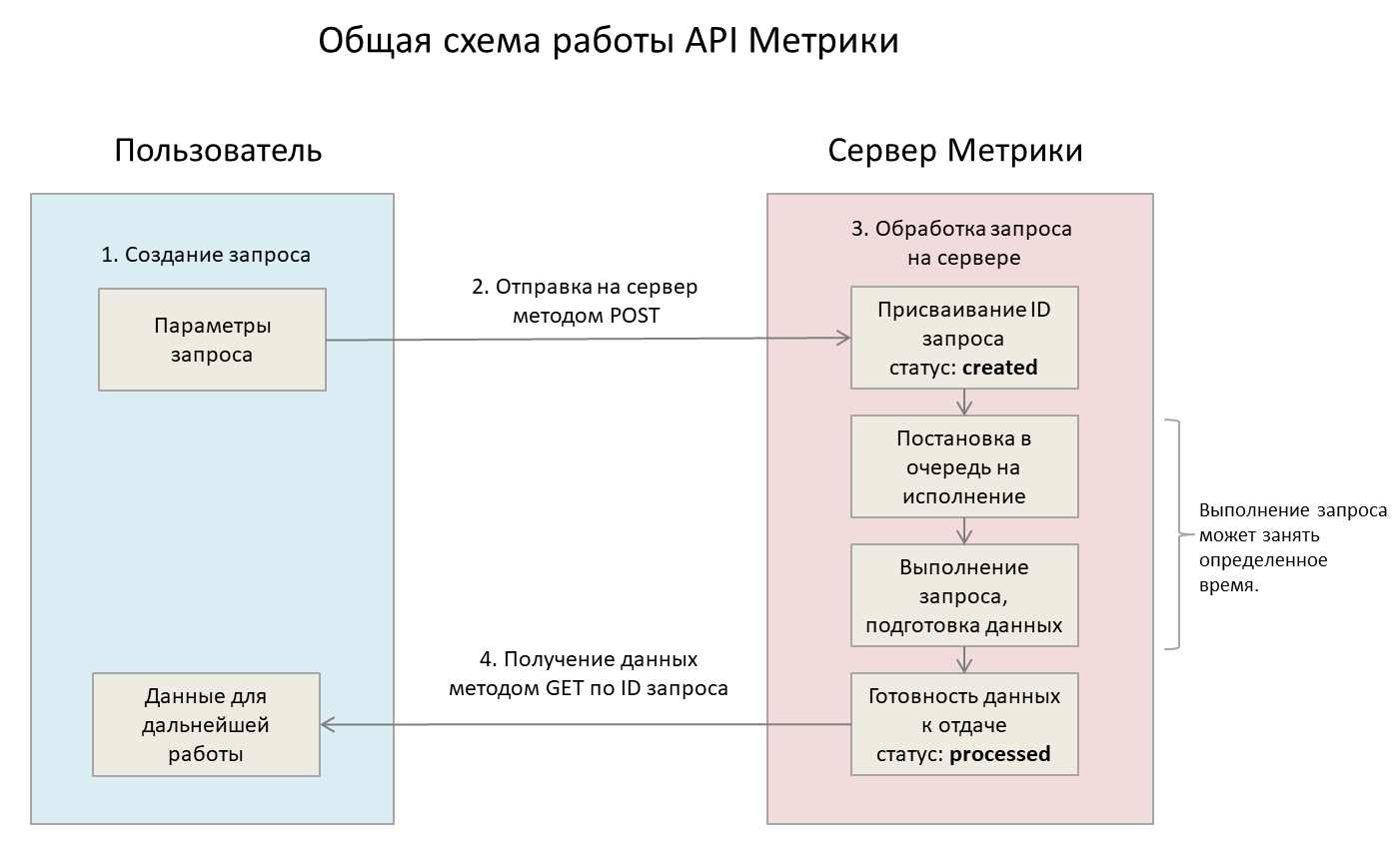
В общем виде схема работы с API Метрики выглядит следующим образом:
- Сначала надо получить авторизационный токен (как это сделать, разберем ниже), а также номер счетчика Метрики, для которого мы будем выгружать логи.
- Для корректного создания запроса необходимо указать его параметры: даты, за которые будем выгружать данные, список полей и тип источника запроса (визиты или просмотры). После установки параметров мы отправляем запрос на сервер Метрики методом POST.
- После отправки запроса, если все прошло успешно, ему присваивается уникальный идентификатор — requestId. После создания на сервере запрос получит статус создан («created») и встанет в очередь на исполнение. Время исполнения запроса зависит от размера запрашиваемых данных, а также от загруженности серверов Яндекса (в среднем выгрузка небольшого объема в несколько тысяч записей не должна занять более 15-30 минут) .
- Когда запрос обработается, его статус изменится на обработан (processed), а данные станут доступны для выгрузки и дальнейшей работы с ними.
Получаем OAuth токен Яндекса
Чтобы получить специальный авторизационный токен от Яндекса:
1. Войдите в аккаунт, который имеет доступ к нужным счетчикам Метрики.
2. Для работы через приложение надо создать приложение. Для получения OAuth-токена пройдите по ссылке.
3. При создании приложения укажите его название (любое).
В разделе «Платформы» выберите «Веб-сервисы», в качестве Callback URI #1 укажите следующее значение https://oauth.yandex.ru/verification_code как на скриншоте.
В разделе «Доступы» выберите Яндекс.Метрика и выберите пункт «Получение статистики, чтение параметров своих и доверенных счетчиков»:
После выбора параметров нажмите кнопку «Создать приложение».

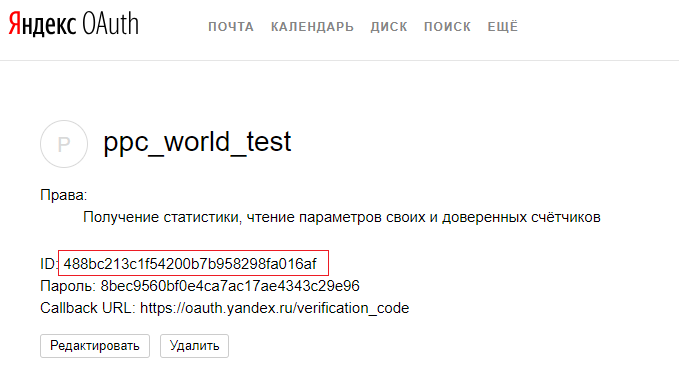
4. После создания приложения вы увидите следующую страницу. Вам необходимо скопировать идентификатор ID (выделен красной рамкой).
5. Далее вам необходимо пройти по следующей ссылке, вставив в ссылку идентификатор:
https://oauth.yandex.ru/authorize?response_type=token&client_id=<идентификатор приложения>
![]()
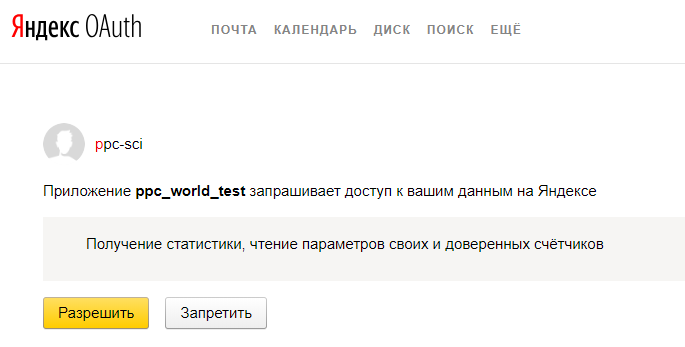
6. Если вы все сделали правильно вы увидите следующую страницу, где вам необходимо нажать кнопку «Разрешить».
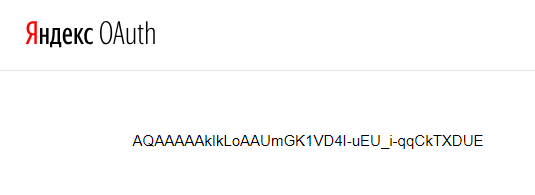
7. После предоставления доступа система сообщит ваш OAuth-токен, как показано на скриншоте ниже. Скопируйте его и сохраните в надежном месте, срок его действия — один год, и он будет использоваться при каждом взаимодействии c Метрикой по API.
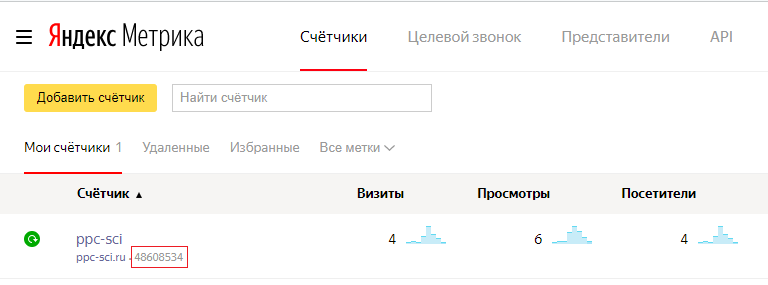
8. Кроме токена авторизации вам также понадобится номер счетчика Яндекс.Метрики — counterId. Номер счетчика вы можете взять в интерфейсе Метрики в разделе счетчиков.
Получив токен и скопировав номер счетчика, вы можете воспользоваться скриптом и начать выгружать сырые данные для дальнейшего анализа.
Механика работы скрипта
Перед началом работы создайте специальную папку, в ней разместите два файла run.ipynb и ppc_sci.ym_raw_data.py (основной файл скрипта, актуализирован в мае 2019 года). Для запуска нужно использоваться пакет Anaconda, который уже содержит предустановленные библиотеки, необходимые для работы скрипта.
Запустив оболочку Jupyter и положив в рабочую папку файлы, вы должны увидеть примерно следующую картину.
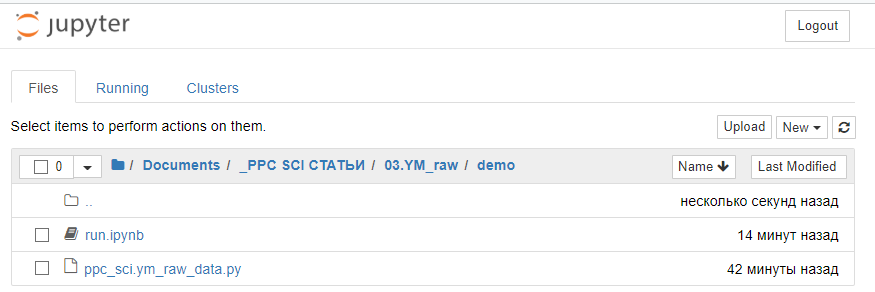
После запуска блокнота run.ipynb вам необходимо указать переменные token и counterId. Для начала работы запустите первую ячейку.
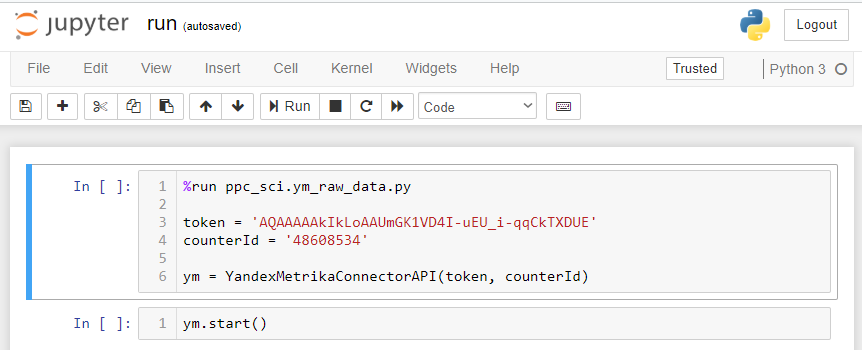
Непосредственно работа скрипта начнется, когда вы запустите вторую ячейку с командой ym.start().
После старта работы скрипта вы увидите «ГЛАВНОЕ МЕНЮ» с основными вариантами выбора:
- получить список id запросов на сервере — [1];
- создание нового запроса — [2];
- удаление запроса(ов) с сервера — [3];
- записать выгруженные логи в Excel-файл — [4];
- выйти и завершить работу скрипта — [0].
Важно: «ГЛАВНОЕ МЕНЮ» будет возвращаться после каждого выбранного пункта меню, пока вы не завершите работу скрипта.
Для лучшего понимания логики работы скрипта необходимо обязательно подробно изучить раздел «Общая схема работа API Метрики», т. к. структура меню скрипта повторяет логику схемы работы API интерфейса Метрики.
Для начала проверим, существуют ли готовые запросы логов, доступные для выгрузки на сервере. Для этого выберем пункт [1] меню: нужно вбить в поле для ввода цифру «1» и нажать Enter. Если вы не создавали запросы ранее, то никаких запросов на сервере пока нет, о чем вам сообщит скрипт в сообщении. После этого скрипт сразу попросит ввести код следующей операции.
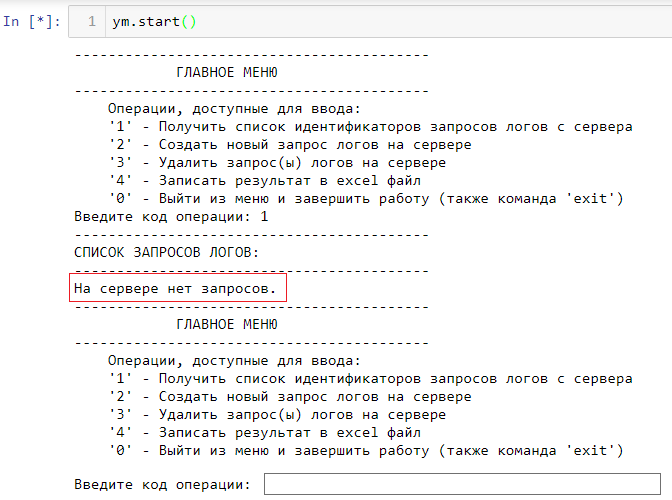
Если вы попробуете ввести несуществующий пункт меню, например цифру «6», то скрипт выдаст ошибку и попросит снова ввести данные.

Давайте создадим новый запрос логов, выбрав код операции [2]. Скрипт попросит указать источник запросов 1 (визиты) или 2 (показы).

Когда вы выберете источник запроса, скрипт попросит указать начальную дату запроса в формате ГГГГ-ММ-ДД. Важно точно соблюдать формат!

Вводим дату и нажимаем Enter.

После начальной даты скрипт запросит вторую, конечную, дату.

После ввода конечной даты скрипт выведет вам идентификатор запроса логов id, а также его статус.
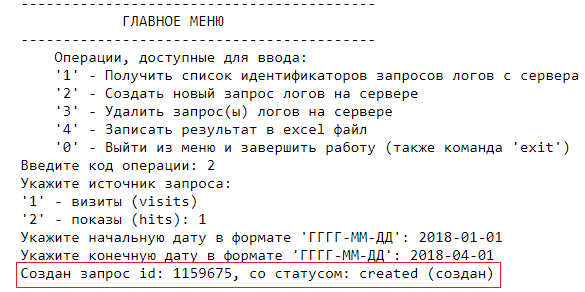
Давайте теперь попробуем получить список запросов с сервера, введя код операции [1]. Как видно на рисунке ниже, список запросов логов выводится в виде списка с подробными характеристиками: id логов, номер счетчика, источник логов (визиты/показы), даты запроса и текущий статус запроса. Так как мы просим список запросов сразу же после создания первого запроса, статус создан (created) еще не успел обновиться, это значит, что запрос еще находится в очереди на обработку и не готов к выгрузке.
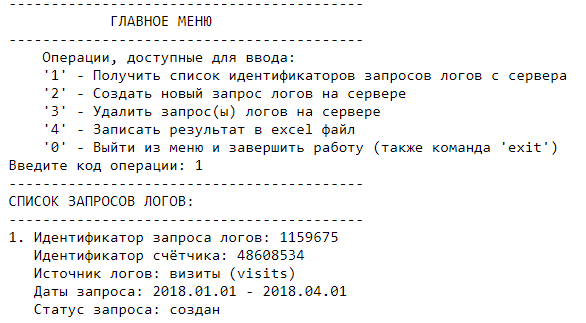
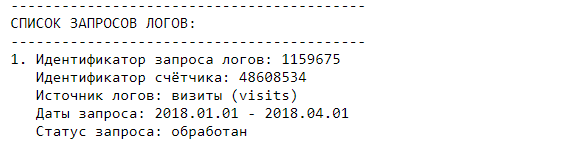
Вызвав запросы на сервере спустя какое-то время (в нашем случае несколько минут), вы должны увидеть, что статус изменился на обработан (processed).
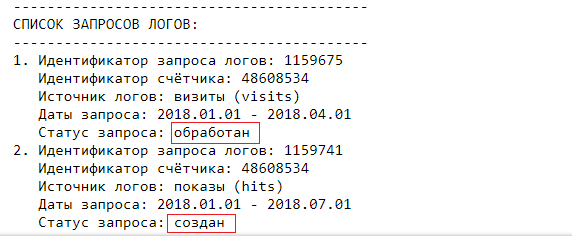
Теперь создадим второй запрос, но в качестве источника выберем показы (hits). Результат полученного списка запросов логов показан ниже.
После того как запрос создан на сервере (имеется id) и статус изменен на обработан (processed), вы можете выгрузить данные для дальнейшей обработки и анализа. Давайте попробуем это сделать. В меню выберите пункт [4] («Записать результат в Excel-файл»).
Скрипт предложит вам выбрать id запроса, который вы планируете выгрузить. Список id запросов, хранящихся на сервере, будет выведен в интерфейсе. Скопируйте нужный идентификатор в поле ввода и нажмите Enter.

После ввода id запроса вы увидите сообщения как на скриншоте. Выделенные предупреждающие сообщения можно игнорировать, они не помешают работе скрипта.

Excel-файл будет записан в папку, где находятся рабочая Jupyter тетрадь и файл со скриптом.
В выгруженном файле будут все доступные поля (смотрите в справке описание полей для визитов и просмотров). Как именно обрабатывать и использовать данные, мы рассмотрим в следующих статьях. Вы можете это делать как в Excel, например, при помощи сводных таблиц, так и с помощью более продвинутых инструментов — языков R или Python.
После выгрузки запросов в Excel мы можем удалить запросы с сервера, т. к. они нам больше не понадобятся. Для этого выберите пункт [3]. Вы можете как удалять отдельные запросы, указывая нужный номер id, так и удалить сразу все запросы с сервера, набрав команду all.
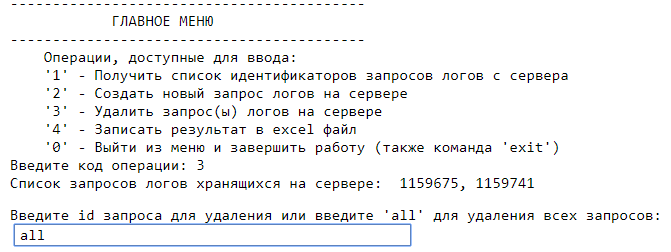
После ввода all скрипт удалит все созданные на сервере запросы.

Для выхода и завершения работы скрипта вам достаточно выбрать пункт [0] или ввести слово exit. Фраза «Работа завершена» говорит о том, что скрипт завершил работу.

Заключение
Возможно, поначалу работа со скриптом покажется вам немного «громоздкой» и запутанной, но освоившись с интерфейсом, вы очень скоро будете создавать запросы не более чем за полминуты, а перспективы, которые откроет для вас работа с исходными данными Яндекс.Метрики, многократно окупит затраченное время. В следующих статьях мы разберем на практике решение задач, связанных с анализом и обработкой логов.
Если у вас есть желание разрабатывать подобные скрипты для автоматизации рабочих процессов, записывайтесь на базовый курс PPC-Scientist.
Ваши вопросы по работе скрипта, а также предложения и идеи новых скриптов оставляйте в комментариях к статье. Всем успехов в настройке.
Ваша реклама на ppc.world
от 10 000 ₽ в неделю

Читайте также

Как за 3 месяца на 77% увеличить количество заказов на кухни в премиум-сегменте — кейс
Теперь ИИ продвигает бизнес, у которого нет сайта: как это и нужно ли вообще вкладываться в сайт





Последние комментарии