
Топ-7 ошибок при сборе семантического ядра для контекстной рекламы
Руководитель группы контекстной рекламы в Риалвеб Дмитрий Багнюк разбирает семь наиболее популярных ошибок, которые возникают из-за несоблюдения правил сбора семантики, и рассказывает, как этих ошибок избежать.


Сбор семантического ядра — один из первых и наиболее важных этапов запуска и масштабирования проекта в контекстной рекламе. Качественная и полная семантика — залог для эффективного продвижения и углубленной оптимизации рекламных кампаний. Тем не менее, многие PPC-специалисты допускают ряд ошибок при сборе семантического ядра, которые ведут к напрасной трате бюджета на продвижение.
Ошибка 1. Не прорабатывать структуру будущего семантического ядра
Перед парсингом (сбором семантики) нужно определить, что именно мы собираем и зачем. Для этого — изучить продвигаемый продукт или услугу, особенности рынка и конкурентную среду. Это нужно и для более полного охвата запросов, и для того, чтобы в самой рекламе говорить с пользователем на одном языке.
Задайте себе несколько вопросов о продукте или услуге:
-
Как называется то, что я предлагаю?
-
Где оно находится географически?
-
Какими техническими и потребительскими характеристиками обладает? (Цена, внешний вид, физические свойства, уникальные преимущества и так далее).
-
Какую проблему решает?
-
Кто моя целевая аудитория?
-
Кто мои конкуренты?
Например, структура семантического ядра для ресторана доставки блюд японской кухни может быть следующей:
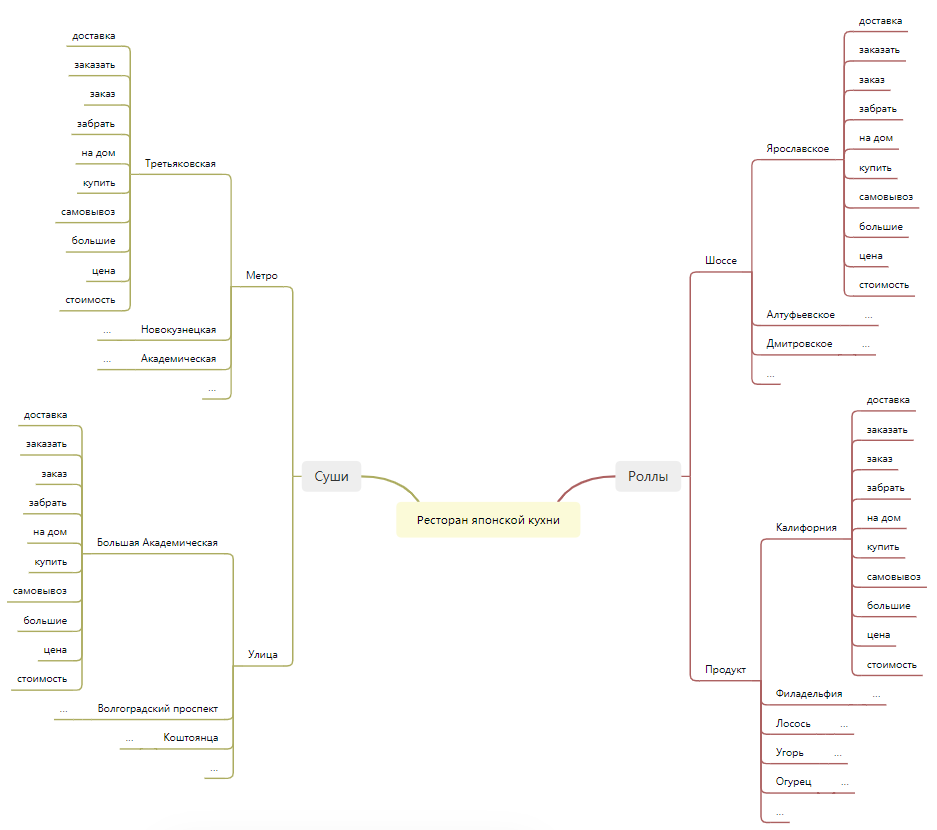
Эта структура предполагает деление семантики по типу доставляемых блюд (роллы и суши) с сегментацией по географическому признаку (улицы, метро, шоссе) и продуктовому признаку (название и ингредиенты конкретных блюд).
Конечно, в реальной семантической структуре количество элементов будет сильно больше, а их проработка детальнее. Так, среди кластеров, которые не представлены на схеме:
-
бренд ресторана;
-
сервисы-конкуренты;
-
районы;
-
округи;
-
локации бизнес-центров, работники которых заказывают блюда ресторана на обед;
-
иные блюда ресторана;
-
общие запросы («где быстро поесть», «заказать японскую кухню» и так далее).
Ошибка 2. Собирать семантику на основе неполной структуры
Логическое следствие ошибки № 1 — собирать семантику по неполной структуре, из-за чего ядро получается тоже неполным. Говоря точнее, ошибкой это становится тогда, когда после составления структуры специалисту кажется, что он учел все что мог.
Чтобы избежать такой маркетинговой близорукости, сделайте следующее:
-
Изучите сайт непосредственно продукта или услуги, его тематические и функциональные разделы.
-
Проведите анализ сайтов-конкурентов.
-
Прочитайте несколько экспертных статей об объекте рекламы. В идеале — те, которые раскрывают объект системно. Структура статьи может стать и частью вашей семантической структуры.
-
Проведите брейншторминг с коллегами, у которых есть опыт запуска в этой нише, с профессионалами на стороне клиента, понимающими свой рынок.
-
Используйте сервисы-помощники (о них — в конце статьи).
Например, вы продаете велосипеды и сопутствующий спортивный инвентарь. Заходя на сайт одного из популярных продавцов, вы видите категории товаров.
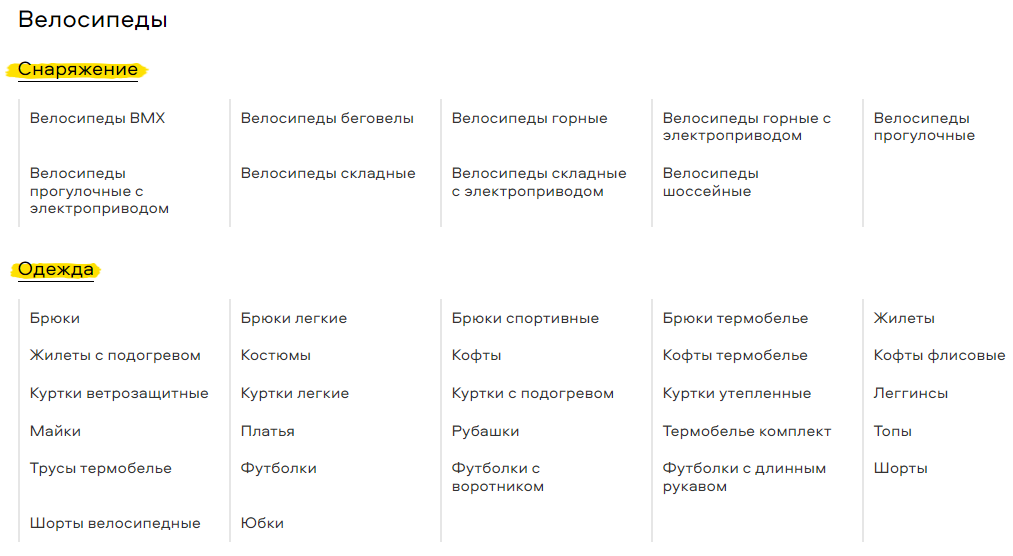
Подумайте: всё ли из того, что предлагает этот сайт, вы уже занесли в свою структуру? Возможно, что-то из этого просто нерелевантно для вас? Возможно, вы не продаете BMX, но в рамках сбора семантики хотите узнать подробнее о горных велосипедах?
Смело заходите в каждый из блоков и благодаря сортировке, расширенным фильтрам, которые конкуренты уже реализовали на своем сайте, определяйте, чего не хватает именно вам в текущем варианте семантической структуры.
Например, велосипеды различаются в зависимости от бренда, размера рамы, пола и возраста покупателя, сезона выхода модели, типа (хардтейл, ригид, двухподвес), назначения (трейл, дерт, кросскантри, эндуро, даунхил), материала рамы и обородувания, хода подвески, типа тормозов и других характеристик — их нужно отразить в семантической структуре.
На основе такой объемной структуры семантическое ядро станет по-настоящему полным. Это позволит учесть максимум запросов и создать большое количество наиболее релевантных объявлений.
Ошибка 3. Игнорировать маски
Это еще один аспект, который нужно проработать до парсинга семантики. Маски — это базовые ключевые слова, которые содержат в себе все остальные. При этом они должны быть конкретны.
Допустим, ваш клиент — крупный застройщик, продающий квартиры в Москве. Спарсить семантику по запросу «квартиры» невозможно — количество таких запросов, включая вложенные, может составить 34,5 млн (данные за декабрь 2022 года).
Если ЖК застройщика находится возле метро «Таганская», то маска для проекта будет «квартира метро Таганская». Такая маска позволит собрать не только запрос «квартира метро Таганская», но и вложенные, многоуровневые запросы, которые сложно проработать в ходе предварительного анализа семантики («квартиры метро Таганская новостройка», «купить квартиру Москва метро Таганская» и другие).
Важный нюанс здесь — опять же, нужно обеспечить полноту. Проработать маски важно не только с опорой на структуру продукта/услуги, но и с точки зрения логических связей, с учетом языковых норм:
-
синонимом слова «квартира» могут быть «студия», «однушка», «2-комнатная», «жилая недвижимость», «жилье», «пентхаус» и другие;
-
вместо слова «метро» пользователи могут писать сокращенно «м» (важно зафиксировать ее оператором «+», чтобы Яндекс Директ учитывал ее при показе рекламы);
-
для «Таганской» также употребимо разговорное слово «Таганка».
Таким образом получается маска:
квартира/студия/однушка/2-комнатная + м/метро + Таганская/Таганка
Чтобы расширить эту маску, можно включить в нее и другие синонимы, а также близкие по значению фразы, аббревиатуры, сленговые выражения, латиницу или кириллицу (особенно актуально для иностранных названий брендов: пользователи могут искать «леруа мерлен» или «Leroy Merlin») и вообще всё, что может встречаться в запросах.
Ошибка 4. Не использовать операторы
Вернемся к примеру выше. На самом деле, основу для маски правильнее было бы составить так:
(студия|квартира|однушка|2-комнатная) (+м|метро) (!Таганская|Таганка) -снять -вторичка -аренда -сутки
Такую маску тоже можно расширить в зависимости от целей сбора и особенностей проекта. В ней использовано сразу несколько символов и операторов, причем все они помогают сделать парсинг более качественным и не тратить лишние усилия:
-
() и | позволяют группировать слова, автоматически перемножая их в ходе парсинга. Без них для каждого сочетания всех слов пришлось бы вручную писать отдельную маску.
-
+ фиксирует букву «м», обозначающую здесь «метро».
-
! фиксирует написание слова «Таганская». Так мы избегаем ненужного пересечения семантики (кроме метро «Таганская» есть еще «Таганский» район).
-
— удаляет из выдачи запросы, которые мы прогнозируем как наиболее часто встречающиеся из нерелевантных. Это сильно упрощает дальнейшую чистку семантики, хотя основная работа по чистке всё равно будет позже. В примере с ЖК наиболее частые минусы — это семантика по аренде и вторичному жилью. При минусации учтите, что Яндекс Директ учитывает все словоформы минус-фразы, так что их вбивать не нужно.
Об этих и других символах и операторах Директа можно прочитать в справке.
Ошибка 5. Проводить поверхностную кластеризацию
Кластеризация — еще один значимый принцип качественной проработки семантики, который особенно акутален при сборе крупных семантических ядер (10 000 ключей и больше).
Кластеризация предполагает деление полученной в результате парсинга и обработки семантики на определенные логические блоки. В отличие от структуризации, о которой было сказано ранее, кластеризация отвечает скорее не на вопросы «Как собирать?» и «Что собирать?», а на вопрос «Как работать с тем, что собрали?».
Семантику можно кластеризовать как в соответствии со структурой продукта/услуги, которую проработали ранее, так и с опорой на новую логику, нацеленную на размещение и оптимизацию рекламных кампаний.
Например, возможны следующие подходы к кластеризации.
По частотности. Вся семантика делится на три блока:
-
высокочастотная (в среднем, более 10 тысяч показов);
-
среднечастотная (от 1 до 10 тысяч показов);
-
низкочастотная (менее 1 тысячи показов).
Количество запросов для отнесения к каждому из блоков может быть индивидуальным для каждой сферы. К примеру, в узких нишах более 1000 показов уже может считаться высокой частотностью. В соответствии с этой логикой и происходит деление семантики на уровне рекламных групп и компаний.
Например, для банка запрос «кредит наличными» будет высокочастотной группой — около 370 000 показов. «Оформить заявку +на кредит наличными» — среднечастотной, около 2800 показов. «Оформить кредит наличными онлайн +с моментальным решением» — низкочастотной, около 250 показов. (Данные за декабрь 2022 года.)
В такой группировке важно провести кросс-минусацию, чтобы избежать пересечений по вложенным запросам и, следовательно, внутренней конкуренции.
В соответствии с особенностями и ключевыми характеристиками продукта/услуги. Как вариант в проекте сферы «Недвижимость» — можно выделять кампании по бренду, географии, конкурентам, общим запросам (старт продаж, инвестиции в недвижимость, IT-ипотека).
По назначению семантики. Наиболее часто выделяют запросы:
-
Транзакционные — они содержат любые призывы к совершению действия («купить диван +в москве», «записаться на массаж»).
-
Информационные — они помогают найти ответ поставленный вопрос («сколько лететь до Турции», «зачем нужна кофемашина»).
-
Навигационные — они ведут пользователя на конкретный сайт.
-
Нейтральные — их нельзя отнести ни к одному из видов («лечебное средство», «дизайн интерьера», «макароны»).
Транзакционные группы с большей вероятностью способствуют совершению целевого действия, однако чаще всего такие запросы более узкие и не позволяют обрабатывать запрос на всех этапах пользовательской воронки.
По смысловой группировке. Иногда семантики настолько много, что на проработку SKAG-структуры (Single Keyword Ad Groups; 1 группа = 1 ключевая фраза) ушло бы слишком много времени, хотя, по нашему опыту, SKAG-сегментация рекламного кабинета все еще остается лучшей практикой.
В этом случае возможна группировка по смысловой направленности ключей.
Например, в охранном агентстве направление «Охрана квартир» можно разделить на несколько групп, среди которых будут:
-
ЧОП («квартира ЧОП», «охрана квартир ЧОП»);
-
цена («квартира под охрану цена», «охрана квартиры цена в месяц»);
-
пульт («стоимость пультовой охраны квартиры», «пультовая сигнализация в квартиру»);
-
установка («установка охранной системы в квартире»).
Смешанные и иные подходы к кластеризации. Лучшая кластеризация семантики — это работа сразу по нескольким направлениям, поскольку единой правильной логики кластеризации просто не существует. Поверхностная и недостаточно детально проработанная кластеризация сводит результаты качественного парсинга и обработки семантики к минимуму.
Ошибка 6. Собирать семантику всю и сразу
Сбор семантики — длительный и трудоемкий процесс, а окончательное заполнение крупных кабинетов может занять не один день.
Чтобы сэкономить время, стоит приоритизировать семантическое ядро, то есть собрать и использовать для таргетинга сначала самую эффективную семантику. Например, наиболее релевантные транзакционные запросы, общие ключи, в наибольшей степени описывающие продукт/услугу, брендовую семантику, семантику по ключевым конкурентам, наиболее маржинальным и приоритетным направлениям бизнеса.

Для продвижения жилого комплекса в Москве «зелеными» (наиболее приоритетными) блоками будут бренд, ключевые конкуренты (близость к нашему ЖК, схожесть экспозиции, позиционирования, цены), расположение ЖК (метро Нагорная, Нахимовский проспект, Нагатинская, округ ЮЗАО, районы Нагорный и Котловка), а также интент старта продаж.
В результате вместо сбора семантики по 30 структурным элементам сначала собираются только 11 наиболее целевых. Это позволяет быстрее запустить кампанию и провести первичную оптимизацию.
Ошибка 7. Пренебрегать сервисами автоматизации
Существует множество сервисов, которые помогают избежать большинства ошибок выше. Они не только позволяют находить новые инсайты, но и сокращают время на сбор семантического ядра, автоматизируют часть задач PPC-специалиста, снижают риск влияния человеческого фактора (хоть он и остается по-прежнему высоким).
Можно опираться на данные таких сервисов:
-
Wordstat от Яндекса, главный помощник. Среди преимуществ — возможность оценки региональной популярности и динамики запросов, разбивка по типам устройств, слова-подсказки.
-
Букварикс. Возможен поиск по одному слову или по списку слов, анализ одного или нескольких доменов конкурентов с выводом отчета по их семантическом ядру, сравнение доменов между собой.
-
Словари. Сервисы, позволяющие посмотреть синонимы, антонимы, ассоциации, гиперонимы, гипонимы по заданным словам, что помогает повысить качество и полноту семантического ядра. Например, Reright, «Синонимайзер», «Карта слов» и другие.
-
Сервисы конкурентного анализа. Они предоставляют информацию о запросах, текстах, бюджетах, трафике конкурентов, позволяют произвести сравнение с конкурентами, подобрать новые ключи, посмотреть пересечение семантики. Например, SpyWords, Key.so, SimilarWeb и другие.
-
Keyword Tool. Примечателен тем, что позволяет собирать ключевые слова на основе подсказок YouTube, Bing, Amazon, eBay и иных систем.
Есть и другие сервисы автоматизации, помогающие при сборе семантики. Конечно, если тратить на работу с ними много времени, это тоже ведет к неэффективности. Большинство из них решает схожие задачи, поэтому задача специалиста — понять, с чем действительно стоит работать, а что дает только лишнюю нагрузку.








Последние комментарии