
Семплирование данных: что это и как с этим бороться
Когда нужно проанализировать большой объем данных в аналитических системах, нередко можно столкнуться с семплированием. О том, что это такое, расскажет младший веб-аналитик агентства icontext, входящего в iConText Group, Валерия Андреева.

В этой статье рассмотрим:
Что такое семплирование данных
Семплирование — это статистический способ обработки данных, при котором общее представление о данных строится на основе определенной части всех данных, называемой выборкой.
Допустим, у вас есть мешок с тысячью шариков, и вы хотите узнать, сколько из них синего цвета. Вместо того, чтобы тратить долгое время на пересчет всех шариков, вы можете случайным образом вынуть несколько и проверить, сколько из них синего цвета. Основываясь на этом образце, вы можете сделать вывод о количестве шариков нужного цвета в мешке.
Это грубый пример выборки данных. Но он отражает главную пользу данного метода — семплирование позволяет быстро предоставить данные и сделать вывод о чем-то, игнорируя возможные недостающие данные. Однако отсюда вытекает и главный минус — мы получаем не точные, а приблизительные данные, поэтому есть риск получить искаженный результат.
В системах аналитики данный метод применяется для оптимального соотношения скорости загрузки отчета и точности представления данных.
Как понять в системах веб-аналитики, что данные семплированы
В Google Analytics точность представленных данных обозначается значком щита рядом с названием отчета.
Если щит зеленого цвета, значит семплирование не применялось. Если желтого — отчет создан на основе выборки, при этом процент выборки можно увидеть, наведя курсор на значок.
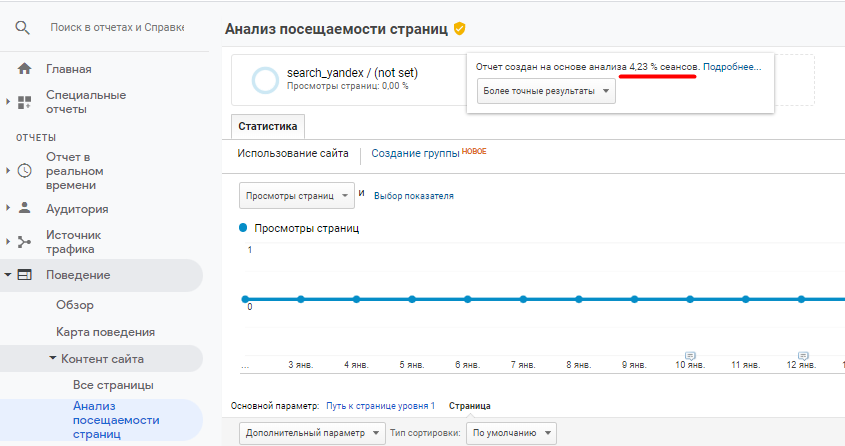
В Яндекс.Метрике процент семплирования указывается в элементе «Точность».
Пример из отчета «Источники, сводка»:
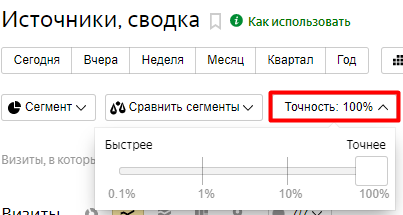
Яндекс.Метрика имеет преимущество в управлении семплированием — точность данных всегда можно настроить. В то время как в Google Analytics часто нет доступа к управлению процентом выборки, если применено семплирование.
Когда возникает семплирование
Google Analytics для создания отчетов сначала собирает необработанные данные, затем он агрегирует их и сохраняет в отчетах по умолчанию (стандартных).
Пять групп отчетов по умолчанию:
-
В реальном времени;
-
Аудитория;
-
Источник трафика;
-
Поведение;
-
Конверсии.
Все отчеты из этих групп по умолчанию не являются семплированными.
Но иногда требуется изменить отчеты по умолчанию, чтобы получить больше информации. Может появиться необходимость добавить новый фильтр, дополнительную метрику, новый сегмент или создать собственный (специальный) отчет. При каждой такой настройке, Google Analytics сначала проверяет отчет по умолчанию, чтобы узнать, доступны ли запрашиваемые вами данные.
Если соответствующие данные недоступны, Google Analytics проверяет количество сеансов. Если их слишком много, тогда Google Analytics берет выборочные данные для предоставления отчета.
Поэтому можно выделить следующие основные причины семплирования:
-
превышение порога обрабатываемых данных (ниже мы описали лимиты для разных версий Google Analytics);
-
создание пользовательского отчета;
-
применение сегмента;
-
добавление в отчет дополнительных параметров;
-
превышение лимита количества строк в выведенном отчете (1 млн строк).
Также стоит отметить, что у каждой версии Google Analytics различаются ограничения по количеству сеансов, при которых применяется семплирование данных.
В Universal Analytics семплирование возникает в специальных отчетах, когда в них собираются данные по более чем 500 тысяч сеансов на уровне ресурса для любого выбранного диапазона дат. В отчетах-картах («Пути пользователей», «Карта поведения», «Карта событий», «Карта целей») обрабатывается не более 100 000 сеансов.
В Google Analytics 360 этот порог выше — 100 миллионов сеансов для любого выбранного диапазона дат на уровне ресурса.
В Google Analytics 4 семплирование обычно применяется в категории «Исследование», когда запрашиваются данные о событиях, количество которых более 10 миллионов.
Что касается Яндекс.Метрики, то здесь похожие причины получения семплированных данных:
-
если данные предоставляются по визитам, количество которых более 1,5 млн;
-
если количество элементов в отчете на странице выдачи превышает 100 000.
Чем может быть опасно семплирование
Как уже разобрано выше, выборка данных показывает приблизительный результат. Поэтому, если нужно провести оценку точных показателей, например, узнать точный коэффициент конверсии, то семплированный результат может сильно отличаться от точного.
Предположим, процент выборки — 85%. На основе таких данных можно сделать вывод — скорее всего, он будет обоснованным и позволит получить корректное представление.
Но чем ниже этот процент, тем, соответственно, больше искажение. Если в отчете представлено 1000 сеансов, и при этом доля выборки 1%, то это будет означать, что результаты данных приводятся на основе 10 сеансов, а данные по оставшимся 99% останутся нетронутыми.
Это риск упустить ценную информацию и потерять деньги, если, к примеру, на основе семплированных данных вы строите вывод об эффективности рекламной кампании.
Также из-за семплирования вы упускаете возможности, которые можно было бы заметить, если бы данные были точными. Например, увидеть закономерность и построить прогноз.
Как избежать семплирования
-
Самый очевидный способ получить полные данные — сократить выбранный период представления данных. При этом можно экспортировать данные за каждый период в Excel или Google Sheets и провести анализ в этих системах, объединив данные по выгруженным периодам. В этом случае, возможно, придется многократно извлекать данные и это займет немало времени, при этом нет гарантии, что даже за самый маленький промежуток — один день — полученные данные не будут семплированы. Так что и в этом случае не всегда возможно избежать полного отсутствия выборки.
-
Настройка фильтра данных в представлении также может помочь избежать семплирования. Но это подойдет в том случае, если требуется периодически проводить анализ какого-то заданного сегмента, а не просмотреть определенные данные разово. Например, если периодически возникает необходимость анализировать данные только по органическому трафику, можно создать новое представление и в нем отсечь всё лишнее, оставив только органический трафик.
-
Если вы пользуетесь Google Sheets, можно использовать расширение Google Analytics для ручного извлечения данных GA в отдельные временные диапазоны, а затем использовать формулы или сводные таблицы, чтобы снова собрать все это вместе. Загляните в руководство от Google по настройке выгрузки.
-
Можно воспользоваться специальными платными софтами, которые работают по аналогии с третьим пунктом. Они разбивают данные на более мелкие временные рамки, а затем объединяют их обратно в один диапазон, в основном избегая выборки (смотрите примечание ниже о данных на уровне пользователя).
-
Если вы используете обычный Google Analytics, то, может быть, вам подойдет способ перейти на платную версию — GA 360, где пороговые значения получения точных данных выше. Даже если будет превышен порог, то отчет без выборки все равно можно запросить. Однако, когда вывод данных превысит три миллиона строк, Google объединит эти строки под одной — other. Но переход на данную версию стоит рассматривать, если вы часто сталкиваетесь с семплированными данными, на вашем сайте более 10 млн хитов в месяц, и годовая доходность может обеспечить вложение в лицензию.
-
И еще один способ — использование хранилищ данных. С помощью автоматизации хранилища данных, можно существенно сокращать время, необходимое для извлечения, передачи и загрузки данных, чтобы составить отчет и проанализировать его. Одно из самых популярных хранилищ — Google BigQuery, и, если вы используете GA 360 или GA4, то связать их с BigQuery можно, используя бесплатный функционал для связывания в интерфейсе GA 360 или GA4. Для выгрузки данных о поведении пользователей в BigQuery можно также использовать сторонние инструменты, которые помогут собрать данные в несемплированном виде напрямую с сайта в BigQuery.
Примечание. Процесс сбора данных по API затруднителен для случаев, когда нужно выполнить анализ метрик на уровне пользователя. Показатели на уровне пользователя при извлечении данных из API не могут быть точными, так как для анализа поведения пользователей необходимо просматривать данные за период времени. Это означает, что вы не можете извлекать небольшие диапазоны дат, а затем объединять их вместе, если вы собираете пользовательские параметры/показатели.
Ваша реклама на ppc.world
от 10 000 ₽ в неделю

Читайте также

Как настроить BI-аналитику для Директа с помощью Python за 0 рублей — инструкция и видеогайд

Сотрудник спорит и делает минимум? Лечим мотивацию с лидом из Яндекса





Последние комментарии