


В июле 2023 года перестали работать стандартные ресурсы привычной многим системы аналитики от Google — Universal Analytics (UA). Более того, некоторые компании уже до этого столкнулись с ограничениями в работе счетчиков UA и вынужденно перешли на другую систему аналитики.
В качестве новой системы аналитики многие предпочитают Яндекс Метрику. Но, к сожалению, не весь функционал Universal Analytics есть в Метрике, и поэтому приходится работать с сырыми данными через Logs API.
В этой статье разберем, как использовать Logs API Яндекс Метрики для построения воронок. Мы поделимся с вами примерами кода, который вы сможете сразу использовать: достаточно будет поставить на устройство Jupyter Notebook, скопировать в него код и указать нужные шаги воронки.
Кому подойдет настройка воронки с помощью Logs API
Если коротко — тем, кому нужно построить воронку из N шагов. В интерфейсе Метрики можно создать составную цель, но есть некоторые ограничения:
-
сложно заранее предусмотреть все возможные воронки;
-
иногда нужно посмотреть данные до даты создания составной цели.
В Метрике нельзя в тех же сегментах задать очередность посещения страниц, достижения целей и т. д. Но это можно обойти с помощью Logs API.
Обращаем внимание, что такое решение подойдет не всем. Данные будут обрабатываться на вашем устройстве, и если у вас крупный проект, генерирующий миллионы хитов, и старый ноутбук на 4 Гб, то он не справится с обработкой такого объема данных.
Если Logs API не справляется с объемом ваших данных, рекомендуем перейти на Метрику Про. Чтобы ознакомиться с условиями перехода, можете написать нам на analytics@adventum.ru.
Шаг 1. Получить токен
Чтобы воспользоваться скриптом для Logs API, понадобится токен. Для этого:
-
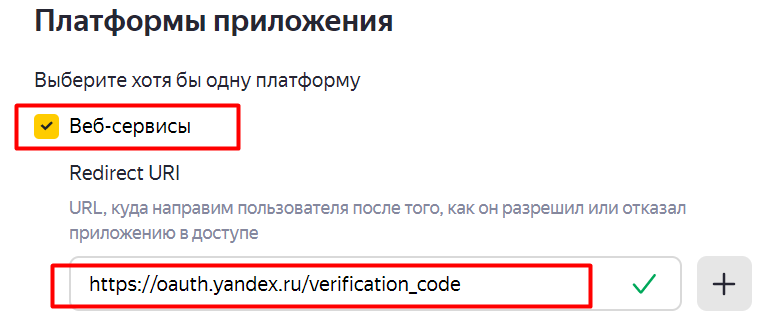
Создайте приложение.

-
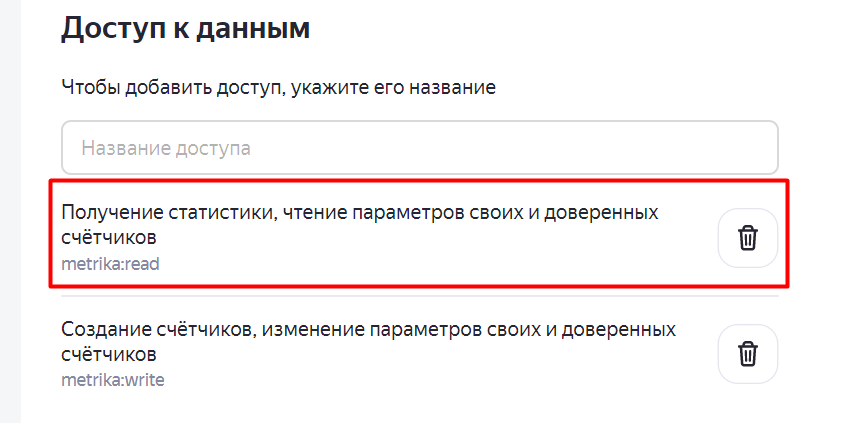
В доступах к данным в приложении выберите «Получение статистики, чтение параметров своих и доверенных счетчиков».
-
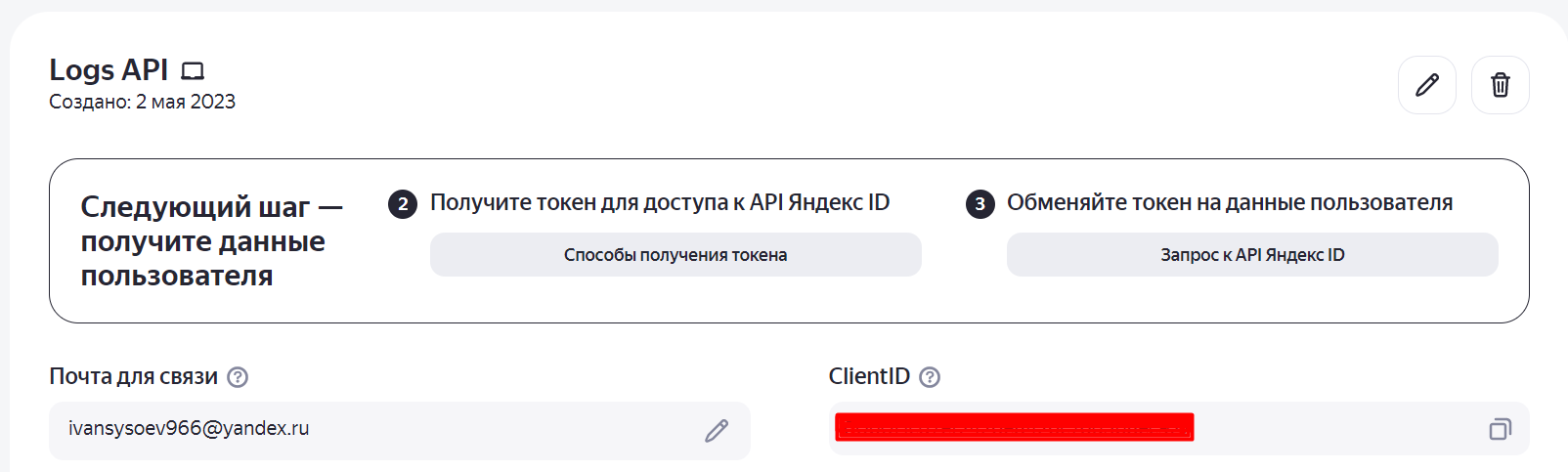
Кликните на кнопку «Создать приложение», и вы окажетесь на странице приложения.
-
На странице вы увидите ClientID. Его нужно скопировать и подставить в ссылку на место abc в примере ниже:
https://oauth.yandex.ru/authorize?response_type=token&client_id=abc
В случае успеха вы получите токен, который можно использовать в дальнейших запросах. А в случае неуспеха появится сообщение об ошибке.


Не передавайте токен третьим лицам, так как с помощью него можно получить статистику всех счетчиков, к которым есть доступ у аккаунта.
Шаг 2. Выгрузить сырые данные
Прежде чем строить воронки, выгрузите сырые данные из Logs API. Сделать это можно с помощью кода.
#ШАГ 1
import requests
import json
import pandas as pd
import pandasql as ps
#-----------------Для заполнения (начало)
token = '' #Укажите ваш токен
YM_ID = 11111111 #Укажите ваш cчетчик
Date_start = '2023-05-08' #Укажите начало периода
Date_end = '2023-05-08' #Укажите конец периода
#-----------------Для заполнения (конец)
#поля для визитов
visit_fields = '' + \
'ym:s:dateTime' + \
',ym:s:visitID' + \
',ym:s:clientID' + \
',ym:s:lastsignTrafficSource' + \
',ym:s:lastsignReferalSource' + \
',ym:s:referer' + \
',ym:s:lastsignUTMMedium' + \
',ym:s:lastsignUTMSource' + \
',ym:s:lastsignUTMCampaign' + \
',ym:s:deviceCategory' + \
',ym:s:browser' + \
',ym:s:visitDuration'
#поля для хитов
hit_fields = '' +\
'ym:pv:dateTime' + \
',ym:pv:watchID' + \
',ym:pv:URL' + \
',ym:pv:isPageView' + \
',ym:pv:goalsID' +\
',ym:pv:referer' +\
',ym:pv:clientID'
header = {'Authorization':'OAuth ' + token}
#Визиты
if visit_fields != '':
r_s = requests.post('https://api-metrika.yandex.ru/management/v1/counter/'+str(YM_ID)+'/logrequests/?source=visits&date1='+str(Date_start)+'&date2='+str(Date_end)+'&fields='+str(visit_fields), headers=header)
str_data_s = json.loads(r_s.text)
print(str_data_s)
#Хиты
if hit_fields != '':
r_h = requests.post('https://api-metrika.yandex.ru/management/v1/counter/'+str(YM_ID)+'/logrequests/?source=hits&date1='+str(Date_start)+'&date2='+str(Date_end)+'&fields='+str(hit_fields), headers=header)
str_data_h = json.loads(r_h.text)
print(str_data_h)
Если код выдает ошибку «Слишком большой интервал», попробуйте удалить прошлые запросы к API.
В нашем примере мы отправляем сразу два запроса к Logs API, чтобы выгрузить хиты и визиты.
В запросах вам достаточно указать:
-
ваш токен;
-
дату выгрузки;
-
номер счетчика.
Дополнительные поля для выгрузки можно найти в документации Яндекса:
Если какого-то примера не хватает, напишите в комментариях.
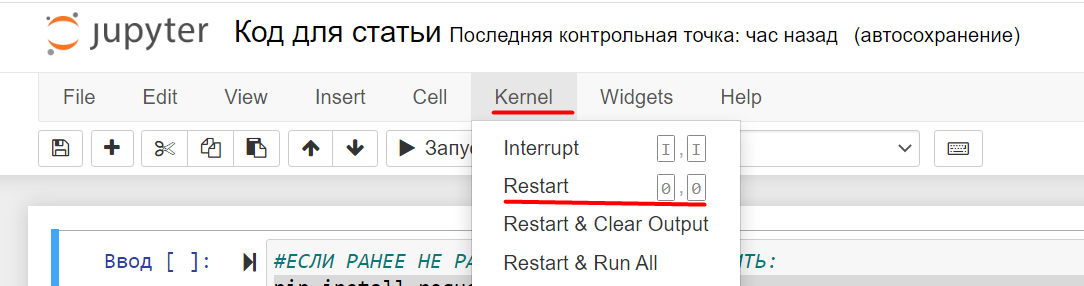
Если при запуске кода у вас возникает ошибка отсутствия библиотеки, вызовите код:
pip install requests
pip install pandas
pip install pandasql
А затем перезапустите kernel.
Также в ходе выгрузки вы можете наткнуться на ошибку «Размер запрашиваемого лога слишком большой...». В этом случае нужно:
-
уменьшить период выгрузки;
-
очистить старые логи запросов.
Код для очистки логов:
#ОЧИСТКА ВСЕХ ЗАПРОСОВ
#БЕЗ НАДОБНОСТИ НЕ ЗАПУСКАТЬ
import requests
import json
import ast
import pandas as pd
import pandasql as ps
#-----------------Для заполнения (начало)
token = '' #Укажите ваш токен
YM_ID = 11111111 #Укажите ваш cчетчик
#-----------------Для заполнения (конец)
header = {'Authorization':'OAuth ' + token}
#Запрашиваем в Logs API реестр запросов
z = requests.get(f'https://api-metrika.yandex.ru/management/v1/counter/{YM_ID}/logrequests/', headers=header)
str_data_z = json.loads(z.text)
request_id = None
for request in str_data_z['requests']:
request_id = request['request_id']
r = requests.post(f'https://api-metrika.yandex.net/management/v1/counter/{YM_ID}/logrequest/{request_id}/clean', headers=header)
print(json.loads(r.text))
Когда вы запросите данные, немного подождите, пока Logs API на своей стороне обработает запрос. Время ожидания зависит от разных факторов: например, числа полей, объема данных, погоды. Ориентируйтесь на 10–15 минут.
После обработки запроса запустите следующий код.
#ШАГ 2
#ПРЕДОБРАБОТКА СЫРЫХ ДАННЫХ
def search_request(fields): #функция для поиска номера запроса
#Запрашиваем в Logs API реестр запросов
z = requests.get(f'https://api-metrika.yandex.ru/management/v1/counter/{YM_ID}/logrequests/', headers=header)
str_data_z = json.loads(z.text)
request_id = None
for request in str_data_z['requests']:
if (Date_start == request['date1'] and Date_end == request['date2'] and \
request['fields'] == fields.split(',')):
#print('Найден нужный запрос')
print('Проверяем статус запроса, ждем статус "processed".')
#print(request['status'])
#если статус нужный, то определяем переменную, в которой будет храниться номер запроса.
if request['status'] == 'processed':
print('Запрос обработан. Получаем ID запроса.')
request_id = request['request_id']
break
return request_id
def return_raw_df(fields): #функция для получения нужного DF
request_id = search_request(fields)
if request_id == None:
print('Выгрузка из Logs API еще не готова. Нужно подождать.')
else:
r = requests.get(f'https://api-metrika.yandex.net/management/v1/counter/{YM_ID}/logrequest/{request_id}', headers=header)
#print('Выгрузили перечень запросов для проверки.')
dict_data = {}
key_dict_data = 0
all_parts = len(json.loads(r.text)['log_request']['parts'])
for part in range(all_parts):
r = requests.get(f'https://api-metrika.yandex.net/management/v1/counter/{YM_ID}/logrequest/{request_id}/part/'+str(part)+'/download', headers=header)
str_data3 = r.text
str_data4 = [s.strip().split("\t") for s in str_data3.splitlines()]
result = str_data4
print('Выгрузка данных с сервера. Часть '+str(part+1)+' из '+str(all_parts))
check_watchIDs = False
for i in range(0, len(result)):
if i!=0 and len(result[i]) == len(fields.split(',')):
column_num = 0
dict_append = {}
#ЗДЕСЬ МОЖНО ЗАШИТЬ ИЗМЕНЕНИЕ ПОЛЕЙ
for column in result[i]:
#ЗДЕСЬ МОЖНО ЗАШИТЬ КАКИЕ ПОЛЯ НЕ ДОБАВЛЯТЬ, ЧТОБЫ НЕ МЕНЯТЬ ЛОГИКУ.
column_name = result[0][column_num].replace('ym:s:dateTime','dateTimeStart').replace('ym:pv:dateTime','dateTimeHit').replace('ym:s:', '').replace('ym:pv:', '')
dict_append[column_name] = column
column_num = column_num + 1
#ЗДЕСЬ МОЖНО ОТФИЛЬТРОВАТЬ СТРОКИ
dict_data[key_dict_data] = dict_append
key_dict_data = key_dict_data+1
dict_keys = dict_data[0].keys()
df_s = pd.DataFrame.from_dict(dict_data, orient='index',columns=dict_keys)
return df_s
if visit_fields != '':
visit_df = return_raw_df(visit_fields)
visit_df_check = True
print('Выгружены визиты')
#visit_df.to_csv('visit_df.csv', index=False)
if hit_fields != '':
hit_df = return_raw_df(hit_fields)
hit_df_check = True
print('Выгружены хиты')
#hit_df.to_csv('hit_df.csv', index=False)
if visit_df_check == True and hit_df_check == True:
print('Объединяем данные')
df_s = visit_df
df = hit_df
dict_data_datetimeEnd={}
key_s=0
for key_s in range(len(df_s.index)):
time1=df_s.iloc[key_s]['dateTimeStart']
time1=pd.to_datetime(time1)
time2=df_s.iloc[key_s]['visitDuration']
time2=int(time2)
time2=pd.to_timedelta(time2, unit='sec')
time3=time1+time2
time3=str(time3)
dict_data_datetimeEnd[key_s] = {
"dateTimeEnd":time3
}
key_s=key_s+1
dict_keys_time = dict_data_datetimeEnd[0].keys()
df_dateTimeEnd = pd.DataFrame.from_dict(dict_data_datetimeEnd, orient='index',columns=dict_keys_time)
df_s.loc[:, 'dateTimeEnd'] = df_dateTimeEnd['dateTimeEnd']
q1 = """
SELECT DISTINCT
df.dateTimeHit,
strftime('%d.%m.%Y',df.dateTimeHit) AS Date,
df.clientID,
df.watchID,
df_s.visitID,
df.URL,
df.goalsID,
df.referer AS Hit_referer,
df_s.referer AS Visit_referer,
CASE
WHEN df_s.deviceCategory = 1 THEN 'ПК'
WHEN df_s.deviceCategory = 2 THEN 'Смартфоны'
WHEN df_s.deviceCategory = 3 THEN 'Планшеты'
WHEN df_s.deviceCategory = 4 THEN 'ТВ'
ELSE 'Unknown'
END AS Device,
df_s.visitDuration,
df_s.lastsignUTMCampaign,
df_s.lastsignUTMMedium,
df_s.lastsignUTMSource,
df_s.lastsignTrafficSource,
df_s.lastsignReferalSource,
df_s.browser,
df.isPageView
FROM df
LEFT JOIN df_s
ON df.dateTimeHit <= df_s.dateTimeEnd
AND df.dateTimeHit >= df_s.dateTimeStart
AND df_s.clientID = df.clientID
"""
dataS=(ps.sqldf(q1, locals()))
print('Данные объединены')
dataS.to_csv('raw_data.csv', index=False)
print('Данные сохранены в raw_data.csv')
else:
print('Нужно запустить код позже')
Результатом может стать ответ, что надо подождать. Тогда просто подождите немного и повторно запустите этот кусок кода. В случае успеха данные о хитах и визитах сохранятся в файл raw_data.csv. Если что-то не сработало, скорее всего, вы столкнулись с одной из двух проблем:
-
Яндекс еще не обработал данные — попробуйте еще подождать;
-
данных слишком много, и устройство пользователя с ними не справляется — в таком случае придется поправить функцию, но для этого уже требуются определенные навыки.
Если файл получился слишком объемным для обработки, скорректируйте функцию return_raw_df (код 3). Вы сможете это сделать, если у вас есть базовый уровень навыков Python и немного фантазии — нужно настроить фильтрацию нужных хитов.
Шаг 3. Построить воронку
Мы хотим закрыть базовые потребности аналитиков при построении воронок, поэтому в качестве шагов используем просмотры страниц и отработку JavaScript-целей. Если вам для воронки нужны другие шаги (параметры визитов, ecom и т. д.), пишите в комментариях. Самое актуальное мы добавим в эту статью или напишем вторую часть.
Код воронки:
#ШАГ 3
steps = []
while True:
content = input("Введите шаг: ")
if content == "stop_step":
print('Последний шаг введен')
#print(steps)
break
else:
steps.append(content)
if steps != []:
dataS = pd.read_csv('raw_data.csv', dtype={'clientID': 'str','watchID': 'str','visitID': 'str'})
#steps = ['/login', '/register']
start_part1_sql = "WITH "
start_part2_sql = """ITOG AS ("""
start_part3_sql = """
SELECT
step_col,
date,
Device,
lastsignUTMCampaign,
lastsignUTMMedium,
lastsignUTMSource,
lastsignTrafficSource,
lastsignReferalSource,
COUNT(DISTINCT visitID) AS Visits
FROM ITOG
GROUP BY 1, 2, 3, 4, 5, 6, 7, 8
"""
for i in range(len(steps)):
step_sql = 'Шаг ' + str(i+1)
print(step_sql)
#проверяем использовать регулярные выражения или нет
if steps[i][0] == '~':
filt = "REGEXP '"+ steps[i][1:] + "%'"
elif steps[i][0] == '=':
filt = "= '" + steps[i] + "'"
else:
filt = "LIKE '%" + steps[i] + "%'"
if i > 0:
join1 = """LEFT JOIN STEP""" + str(i-1) + """
ON dataS.Date = STEP""" + str(i-1) + """.Date
AND dataS.visitID = STEP""" + str(i-1) + """.visitID
AND dataS.dateTimeHit >= STEP""" + str(i-1) + """.dateTimeHit
AND dataS.watchID != STEP""" + str(i-1) + """.watchID"""
join2 = " AND STEP" + str(i-1) + ".visitID is not null"
else:
join1 = ''
join2 = ''
q0 = """
STEP""" + str(i) + """ AS(
SELECT
'""" + step_sql + """' AS step_col,
dataS.dateTimeHit,
dataS.Date,
dataS.clientID,
dataS.watchID,
dataS.visitID,
dataS.URL,
dataS.Device,
dataS.lastsignUTMCampaign,
dataS.lastsignUTMMedium,
dataS.lastsignUTMSource,
dataS.lastsignTrafficSource,
dataS.lastsignReferalSource
FROM dataS
""" + join1 + """
WHERE dataS.URL """ + filt + join2 +"""),
"""
start_part1_sql = start_part1_sql + q0
start_part2_sql = start_part2_sql + """
SELECT *
FROM STEP""" + str(i) + """
UNION ALL
"""
start_part2_sql = start_part2_sql[0:-21] + ")"
final_sql = start_part1_sql + start_part2_sql + start_part3_sql
dataS0=(ps.sqldf(final_sql, locals()))
print(dataS0)
else:
print('Введите хотя бы один шаг.')
Указанный скрипт обрабатывает данные из raw_data.csv. После его запуска появятся поля, в которых нужно указать условия каждого шага. Каждый шаг вводится отдельно.
Когда вы добавите все шаги, введите команду stop_step, и скрипт начнет считать воронку.




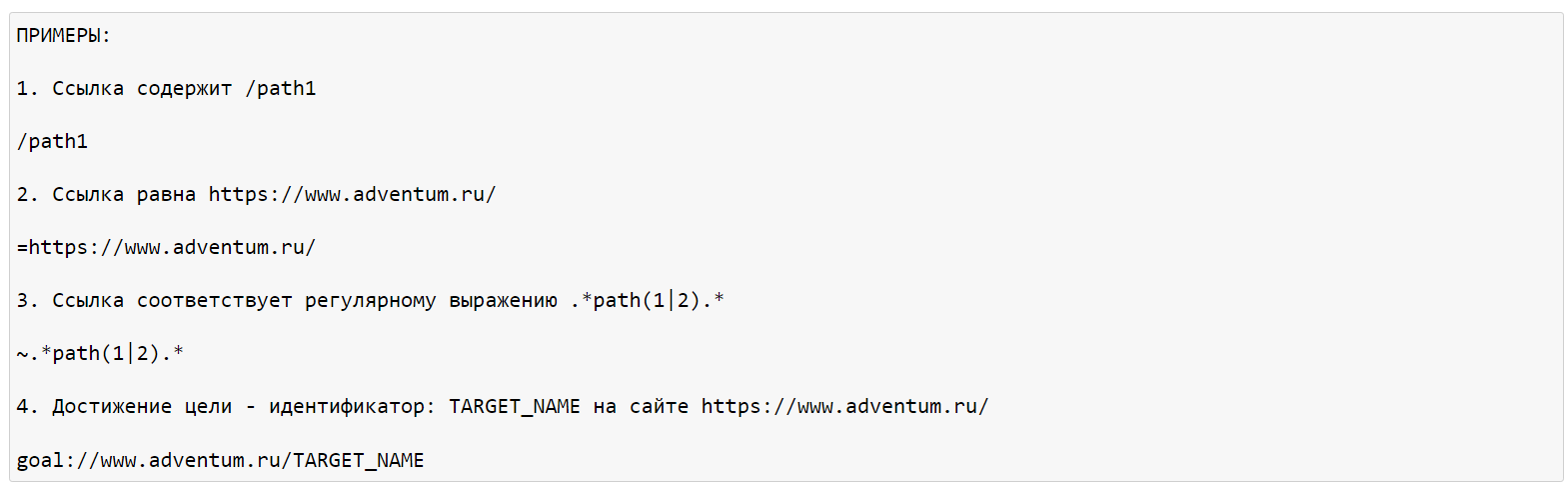
Чтобы добавить регулярное выражение в шаг воронки, используйте символ «~». Чтобы настроить условие «точно соответствует», используйте символ «=».
Примеры ссылок есть в файле для Jupyter Notebook.
По итогу работы скрипта вы получите DataFrame с шагами воронки и детализацией по датам, источнику трафика и типам устройств. В качестве показателя будут отображаться визиты.
С помощью кода результат работы можно сохранить в CSV:
#ШАГ 4
#Сохранение результата
dataS0.to_csv('final_data.csv', index=False)
Файл CSV будет в той же папке, что и файл с кодом для Jupyter Notebook.
С помощью сводной таблицы в Excel можно привести результат к нужному для вас формату. Например, визиты можно складывать.
Закрепим: что нужно, чтобы построить воронку в Метрике
-
Запросить данные в Logs API и подождать.
-
Запустить код для обработки сырых данных.
-
Запустить код для воронок и ввести шаги воронок.
-
Сохранить результат в CSV.
-
Обработать результат из CSV в Excel.
Надеемся, эта статья облегчит вам построение воронки и станет хорошим помощником для освоения Logs API!








Последние комментарии