
Сквозная аналитика и кастомная модель атрибуции для среднего и малого бизнеса без программирования
Специалист по контекстной рекламе в Media 108 Мария Тонковская и координатор агентства по направлению контекстной рекламы Евгений Юдин рассказывают, как с помощью ClientID и без навыков программирования построить аналог сквозной аналитики и пользовательскую модель атрибуции.

Несмотря на большое количество систем сквозной аналитики, у всех из них есть недостатки: цена, процесс интеграции, настройка. Даже в крупных отраслях, таких, как недвижимость, не каждый клиент готов выделять на это дополнительные ресурсы.
Поэтому для одной из девелоперских компаний в Петербурге мы решили самостоятельно выстроить систему сквозной аналитики и кастомную модель атрибуции, которую можно корректировать в зависимости от особенностей бизнеса и поставленных задач.
Как все работает
Чаще всего для аналитики вклада рекламных каналов в продажи используются звонки. Результатом становится примерная картина пути пользователя к сделке. Почему примерная? Потому что если вид продвигаемого товара или услуги подразумевает несколько касаний с рекламными кампаниями, то звонок может быть один, а посещений сайта больше. Как следствие, анализируя только звонки, мы теряем часть рекламных каналов, участвовавших в продаже.
В основу нашей аналитики лег ClientID — анонимный идентификатор, присваиваемый Яндекс.Метрикой каждому уникальному посетителю. Он хранит все сведения о действиях пользователя на сайте: о посещениях страниц, взаимодействии с рекламными кампаниями, совершении конверсий.
Благодаря ClientID мы видим более полную картину и можем точнее присваивать ценность каналам и кампаниям, так как фиксируется намного больше информации, чем просто звонок.
Еще одно преимущество — в конфиденциальности данных. Не каждый заказчик готов передать номера телефонов своих клиентов агентству из-за опасения, что они попадут к конкурентам. ClientID решает эту проблему.
Единственный минус или ограничение — в том, что за один раз можно указывать не более 100 идентификаторов, то есть за раз можно проанализировать поведение максимум 100 пользователей. Это обусловлено ограничением на количество параметров при использовании оператора (=.), подробнее об этом — в справке. Поэтому этот способ подходит бизнесу с небольшим количеством сделок и не моментальным спросом (в случае моментального спроса нет необходимости применять кастомную модель атрибуции, так как ~99% заказов происходят сразу после первого посещения сайта).
При большем количестве ClientID можно выгружать данные поэтапно, отдельными запросами, либо вместо сегментов использовать ClientID в качестве параметра запроса (dimensions).
Итогом построения системы аналитики и модели атрибуции станет таблица, в которой будет видна ценность каждого источника и кампании на пути к продаже. С ее помощью можно будет оптимизировать маркетинговые затраты, отказываясь от неэффективных размещений.
Пользовательская модель атрибуции предполагает, что специалист может самостоятельно выбрать, какую ценность назначить каналу или кампании первого и последнего визита на сайт. Это позволяет подстраиваться под конкретные задачи: увеличение верхнего уровня воронки, сосредоточение на самых конверсионных каналах.
Перед началом
Для подготовки к дальнейшей работе необходим перечень идентификаторов ClientID. Если планируется анализ продаж, то они выгружаются из CRM вместе с датой заключения сделки (о том, зачем нужна дата, станет понятно при создании модели атрибуции). Так как передача данных в каждой CRM может отличаться, подробности уточняйте у менеджеров поддержки CRM.
Все каналы, для которых планируется анализ, должны быть размечены UTM-метками. Обязательные параметры: utm_source, utm_medium, utm_campaign. Остальные параметры опциональны. Например, если планируется аналитика групп объявлений, ключевых слов, то в разметке должны содержаться соответствующие значения.
Создание запроса данных
Дальше необходимо составить запрос через API Яндекс.Метрики, так как веб-интерфейс системы аналитики позволяет фильтровать данные только по одному идентификатору. Когда ClientID больше десяти, процесс становится трудоемким.
Запрос составляется с помощью группировок и метрик. Подробнее с описанием группировок и метрик можно ознакомиться в справке.
Группировка (dimensions) — признак, по которому можно сгруппировать данные, например, браузер, кампания, тип устройства. В контексте нашей задачи нужно использовать группировку по ClientID и параметрам источника трафика.
Метрика (metrics) — это числовая величина, рассчитывается на основе атрибута хита или визита, к примеру: количество визитов, средняя глубина просмотра, коэффициент конверсии.
При создании запроса необходимо учитывать совместимость группировок и метрик. Чтобы задать запрос корректно, в начале названия группировок и метрик используются два варианта приставок:
-
хит — ym:pv:
-
визит — ym:s:
Пример готовой ссылки, которую мы будем использовать для отправки запроса:
https://api-metrika.yandex.net/stat/v1/data.csv?id=11111111&limit=1000&dimensions=ym:s:clientID,ym:s:date,ym:s:lastsignTrafficSource, ym:s:UTMSource,ym:s:UTMMedium,ym:s:UTMCampaign,ym:s:UTMTerm&metrics=ym:s:visits, ym:s:users&date1=2020-01-09&date2=today&filters=ym:s:clientID=.('1579067368','1584950989','1590578020','1590944830','1591214250')
Вместо единиц в параметре id нужно указать номер счетчика, а у вашего логина, который будет отправлять запрос, должен быть доступ на редактирование счетчика.
Используемые в ссылке параметры:
- limit — лимит выгружаемых строк, число прописывается вручную, в зависимости от количества данных;
- dimensions — перечисление группировок данных;
- ym:s:clientID — параметр группировки данных, анонимный идентификатор пользователя;
- ym:s:date — параметр группировки данных, дата визита;
- ym:s:lastsignTrafficSource — параметр группировки данных, последний значимый источник;
- ym:s:UTMSource — параметр группировки данных, рекламная система;
- ym:s:UTMMedium — параметр группировки данных, тип трафика;
- ym:s:UTMCampaign — параметр группировки данных, название рекламной кампании;
- ym:s:UTMTerm — параметр группировки данных, ключевое слово;
- metrics — перечисление метрик;
- visits — метрика, количество визитов;
- users — метрика, количество пользователей;
- date1/date2 — период, за который мы выгружаем данные в формате YYYY-MM-DD (в том числе можно использовать ряд зарезервированных слов, например, today);
- filters — фильтр, в данном случае фильтруем по ClientID;
- ym:s:clientID, идущий после filters — это не параметр ссылки, а параметр вышеописанной переменной — filters — описывает сегмент, по которому выгружаются данные. Дословно можно перевести как «выгрузить данные по всем визитам только данных идентификаторов клиентов», далее — перечисление идентификаторов (до 100).
Затем нужно получить токен, чтобы указать, от какого логина отправляется запрос в API. Для этого необходимо зарегистрировать приложение на Яндекс.OAuth и отправить заявку на доступ к API. Всю информацию о получении токена можно найти в курсе по работе с API.
После генерации ссылки и получения токена можно отправлять запрос по API в Метрику для получения данных по ClientID.
Выгрузка и форматирование данных по ClientID
Для отправки запроса используем сайт ReqBin. С его помощью мы можем отправлять запросы по API в Метрику, не прибегая к программированию на JavaScript, Python или R.
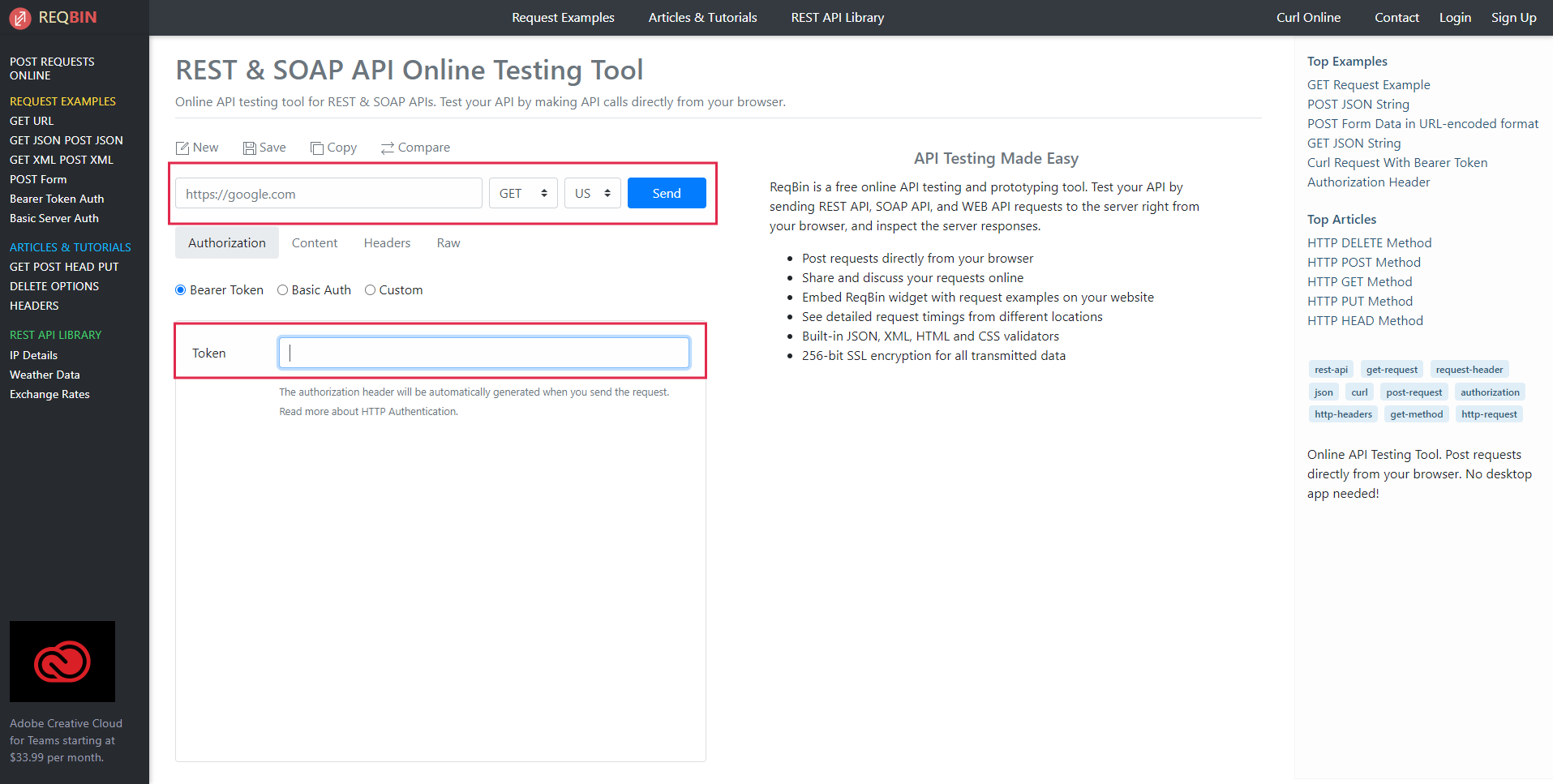
Вставляем сгенерированную ссылку со списком ClientID, вставляем токен, нажимаем на кнопку Send. Готово. Вы прекрасны (на самом деле, еще не совсем).
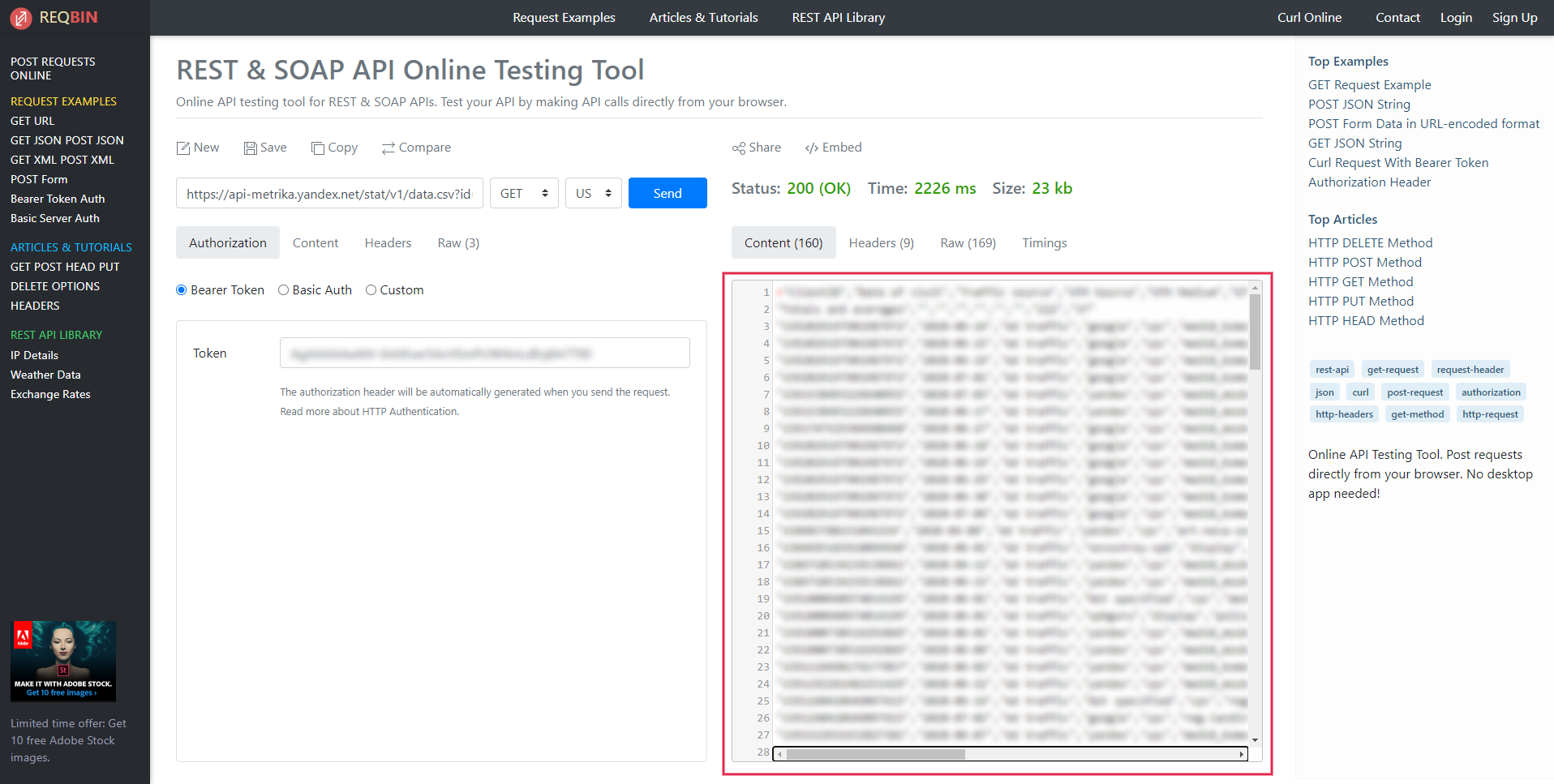
Полученные данные нужно вставить в Excel и разбить по столбцам с помощью запятой. Так выглядят данные сразу после копирования их в Excel:
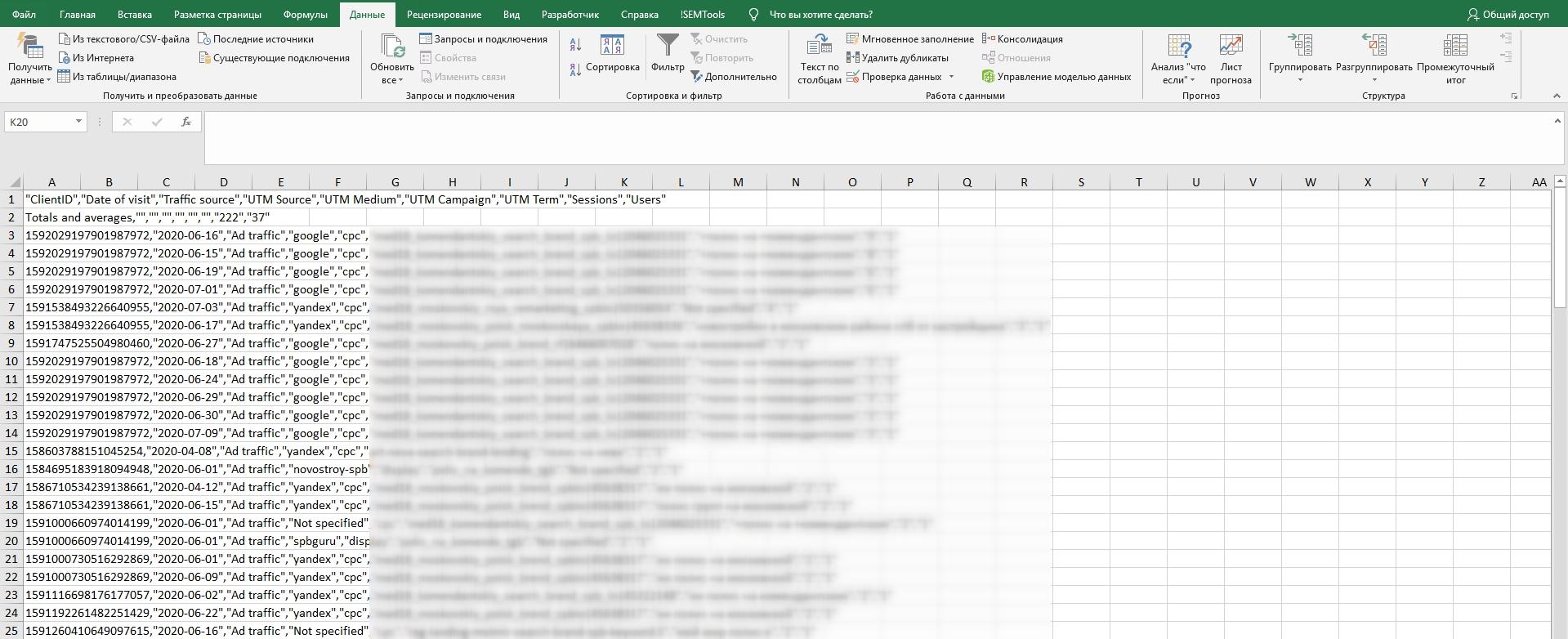
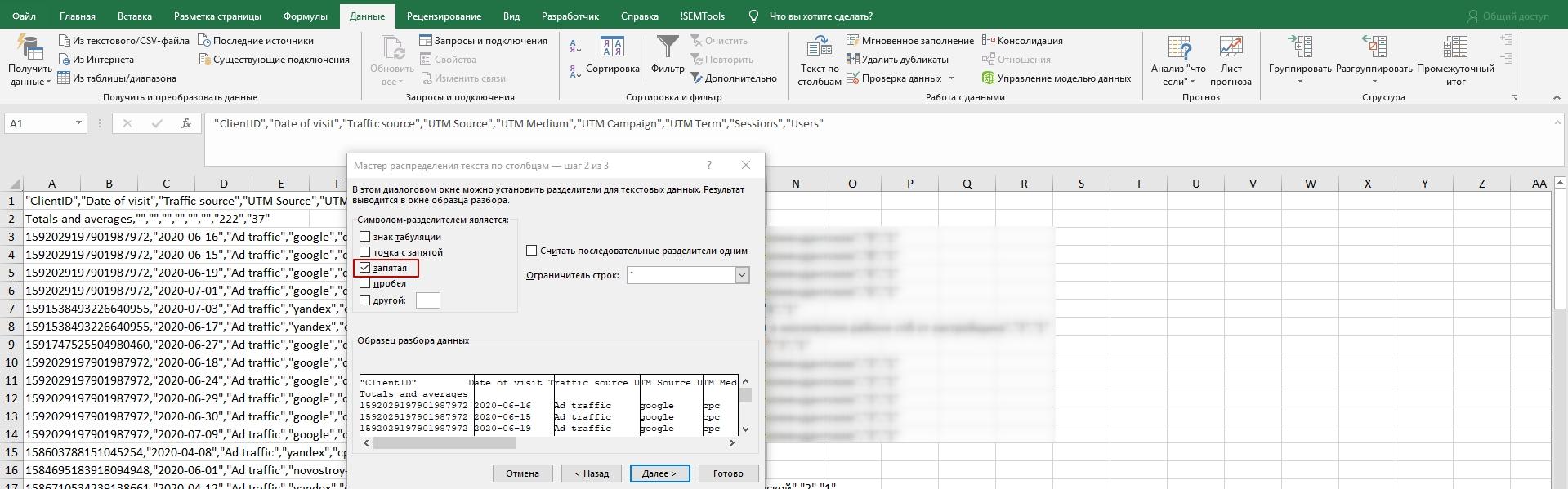
Выделяем столбец с данными, на панели инструментов выбираем «Текст по столбцам», в открывшемся окне «С разделителями».
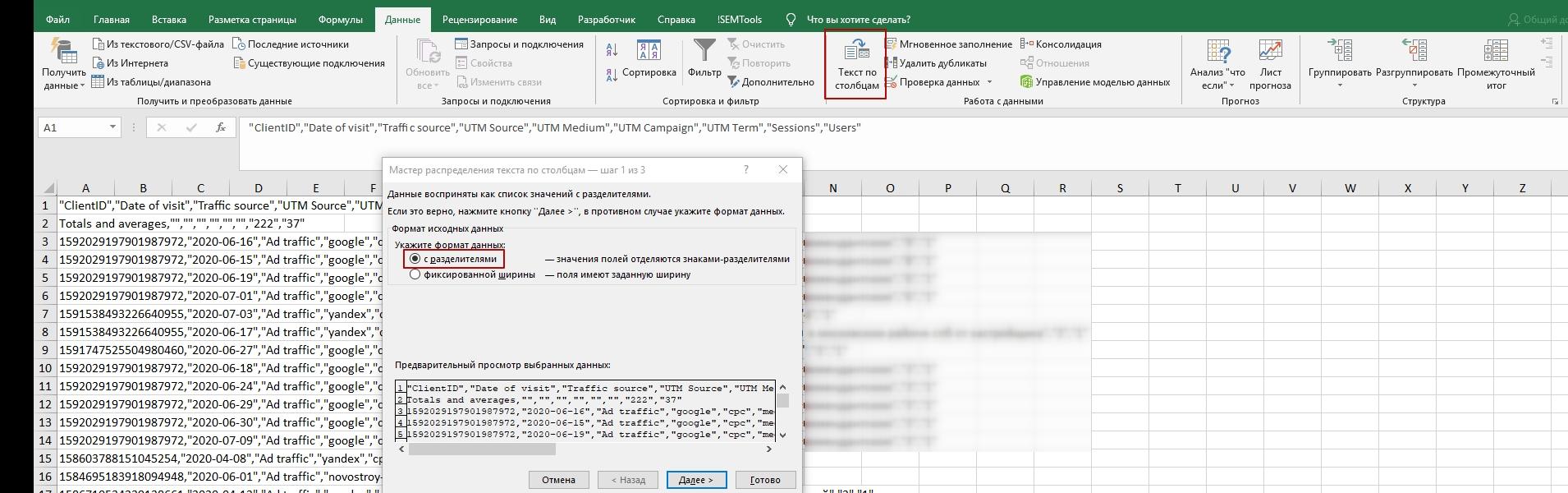
Выбираем «Запятая» и жмем «Далее» — текст разбивается на столбцы.
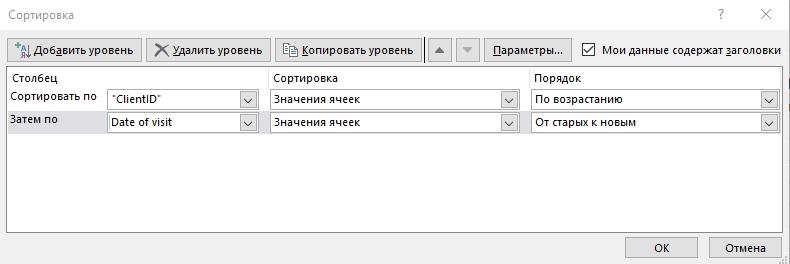
Сортируем данные по столбцу ClientID и по Date of visit (от старых к новым), чтобы видеть путь пользователя к сделке в хронологическом порядке.
Теперь разберемся с магией создания модели атрибуции с помощью формул.
Создание модели атрибуции с помощью формул
Сначала нужно пронумеровать визиты каждого ClientID. Для этого используем формулу «ЕСЛИ»: если ClientID совпадает с идентификатором в предыдущей строке, то номер визита увеличивается на 1. Если не совпадает, значит, это первый визит в цепочке.
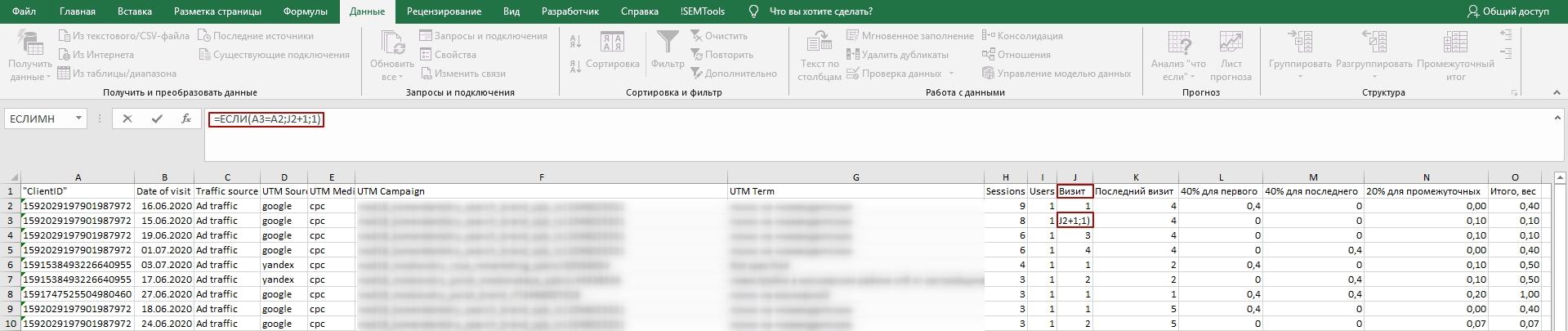
Формула: =ЕСЛИ(A3=A2;J2+1;1), где столбец А — перечень ClientID, J — предыдущий номер визита.
Затем вычисляем номер последнего визита с помощью этой же формулы. Формула в ячейке К2: =ЕСЛИ(A2=A3;K3;J2).
Следующие три столбца — распределение веса между визитами. Мы отдали по 40% первому и последнему, 20% распределили между остальными. Распределение можно менять по своему усмотрению.
Вес первому источнику задается всё той же формулой «ЕСЛИ». Если номер визита — 1, то ему отдается 40% (колонка L2): =ЕСЛИ(J2=1;40%;0). С последним источником аналогично — если номер визита равен номеру последнего визита, то отдаем 40% (колонка M2): =ЕСЛИ(K2=J2;40%;0).
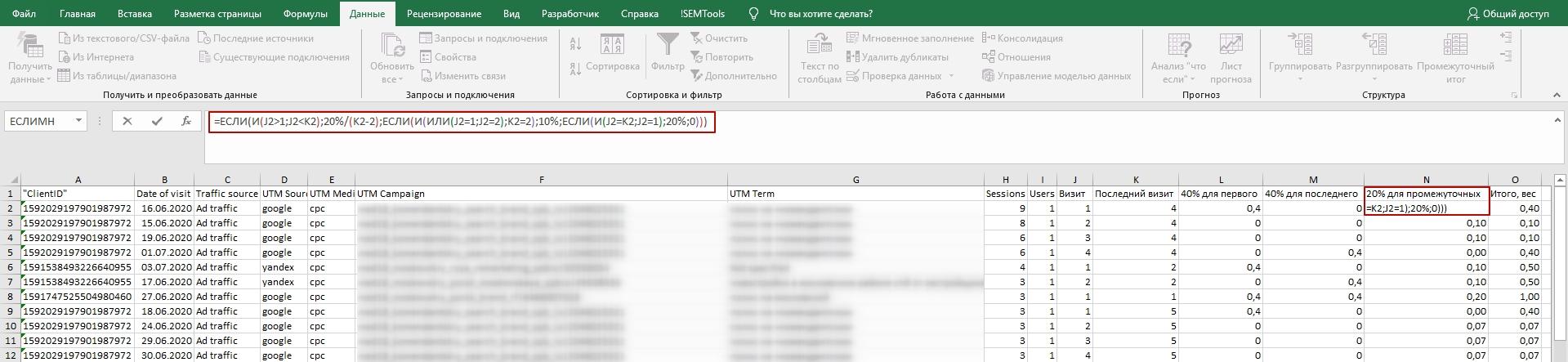
И остается назначить ценность промежуточным каналам, разделив 20% на количество визитов между первым и последним. Если источника всего два, то 20% делятся между первым и вторым пополам. Если один, то весь вес уходит ему.
Формула: =ЕСЛИ(И(J2>1;J2<K2);20%/(K2-2);ЕСЛИ(И(ИЛИ(J2=1;J2=2);K2=2);10%;ЕСЛИ(И(J2=K2;J2=1);20%;0)))
Суммируем все три столбца — теперь вы точно прекрасны.
Фильтрация визитов, произошедших после продажи
После совершения сделки пользователи совершают визиты на сайт. В случае если такие визиты попадают в выгрузку, то им тоже назначается ценность, что не всегда корректно (зависит от того, как часто совершаются повторные покупки). Например, в недвижимости повторные покупки происходят очень редко, поэтому визиты на сайт после совершения сделки совершаются в основном с целью уточнения информации (номер телефона, отчет по строительству, выдача ключей). Однако если один пользователь может совершить несколько покупок с большой вероятностью, то каждый визит на сайт имеет значение, так как может привести к повторной сделке.
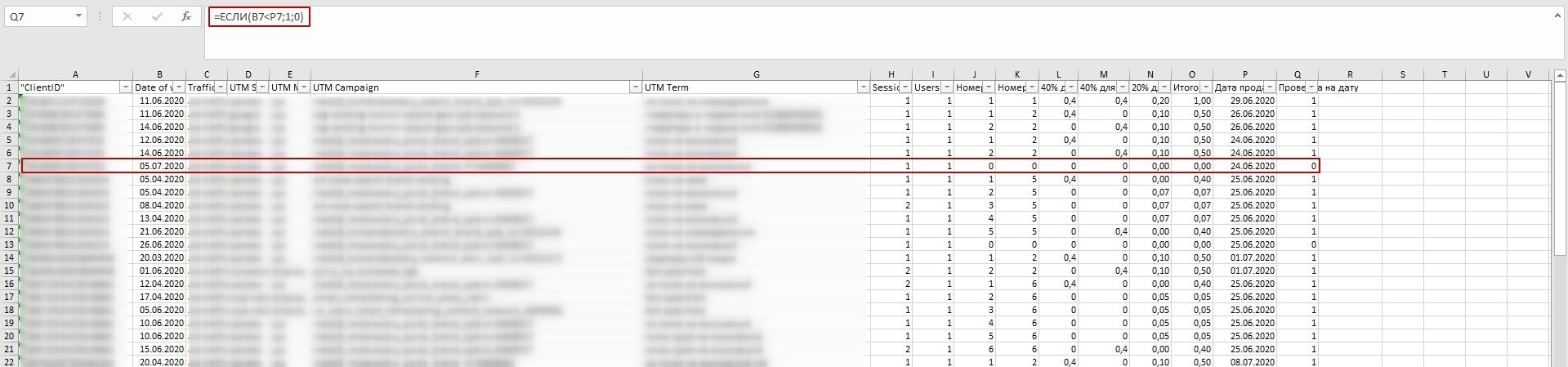
В нашем случае ценность визитам после сделки не нужна. Поэтому мы вручную добавляем в Excel столбец с датой продажи (Q). Далее мы сравниваем дату продажи и визита, и если визит был позже, то он не участвует в расчете ценности и отфильтровывается с помощью формулы =ЕСЛИ(B2<P2;1;0), где B — дата визита, P — дата продажи. Если дата визита больше даты продажи, то ячейке присваивается значение 0. Далее столбец «Проверка на дату» фильтруется по значению «0» и эти строки удаляются, чтобы не учитывать их в расчете.
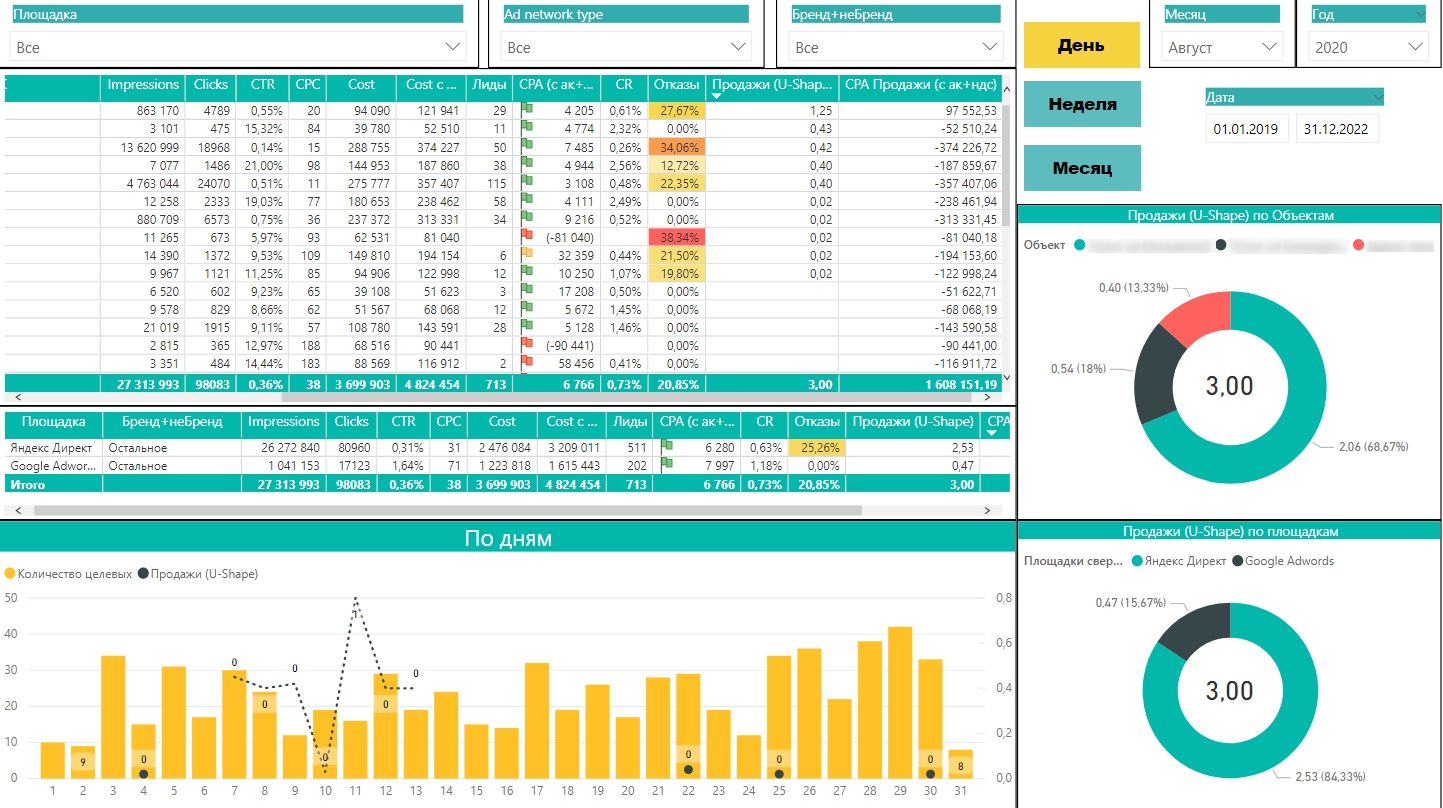
Полученные данные можно подтянуть к расходам по каналам и кампаниям, визуализировать с помощью Google Data Studio или Power BI. Ниже — пример визуализации в Power BI со случайным набором данных, который не имеет ничего общего с реальными данными рекламодателей.
Несколько слов в заключение
Лучше всего этот способ анализа продаж и источников трафика подходит для отраслей с длинным циклом сделки и не очень большим количеством клиентов, например, для недвижимости, авто, ремонтных работ, небольших интернет-магазинов. В таком случае цепочка взаимодействий может быть более 1–2 визитов и есть возможность ограничиться 100 идентификаторами. При необходимости можно сделать несколько выгрузок, по 100 ClientID каждая. Сложности могут возникнуть, когда количество сделок в месяц превысит 1000 и будет неудобно выгружать ClientID сотнями.
Не подходит такой анализ для коротких сделок — касаний с рекламными кампаниями намного меньше, количество сделок — больше, разве что для анализа повторных продаж.






Последние комментарии