
Надстройка !SEMTools для Excel: новый уровень


Около года назад я опубликовал первую версию своей надстройки !SEMTools для Excel. За минувший год было множество минорных обновлений, о которых я рассказывал только на своей странице в Facebook. Но сейчас версия претерпела значительные изменения и улучшения, что можно назвать мажорным обновлением, о чем и хочется рассказать.
Напомню, что эта надстройка расширяет возможности Excel функциями и макросами, которые позволяют специалисту по контекстной рекламе справляться с большинством насущных задач, не составляя громоздких формул и не ища дополнительных решений.
Перед прочтением статьи рекомендую скачать надстройку и установить по инструкции под катом.
1. При скачивании сохраните файл в директории, которую не планируете перемещать и точно не удалите (например, в отдельной папке прямо в корне диска). Не нужно открывать файл.
2. Перейдите в «Параметры Excel» и найдите пункт «Надстройки», нажмите на кнопку «Перейти».

В открывшемся окне через «Обзор» файлов найдите на компьютере скачанный файл надстройки, выберите его и нажмите «ОК». Он должен автоматически появиться в списке и быть с активным чекбоксом:
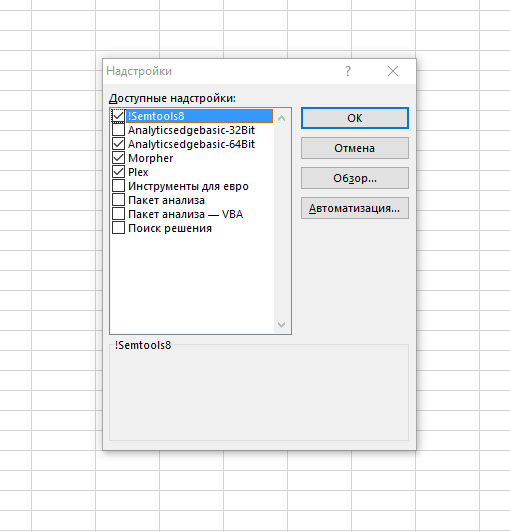
Жмите «ОК». Готово! Теперь все должно работать, при каждом запуске Excel будет загружаться и эта надстройка, и все функции и макросы в ней.
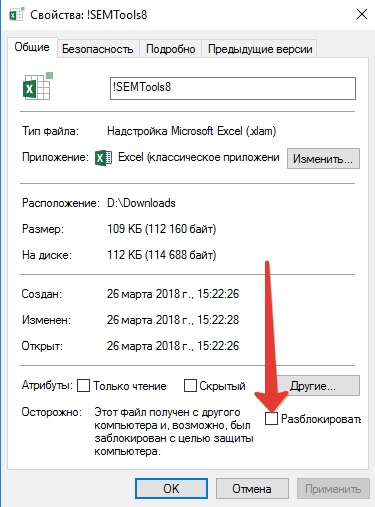
Если панель SEMTools не появляется, возможно, ее блокирует защита операционной системы. Чтобы исправить, нажмите на файл правой кнопкой мыши, откройте свойства и кликните на кнопку «Разблокировать»:
Начнем с визуальных отличий. Так надстройка после установки выглядела раньше:

Не буду углубляться в причины, но все связано с форматом надстройки — раньше это был XLA. Если у вас несколько надстроек XLA, то все они располагаются на одной и той же вкладке «Надстройки», надстройкам нельзя задать приоритет и гарантировать, что все разделы будут отображаться одинаково у разных пользователей.
Сейчас надстройка выглядит так:

У надстройки своя отдельная вкладка и значительно больше функций. Если навести мышь на кнопку или меню, теперь показывается всплывающее описание их функциональности. Изменился и формат надстройки — теперь это XLAM, именно он позволяет реализовывать эти возможности.
Я распределил макросы в разные блоки по методу взаимодействия с данными (мне это показалось наиболее подходящим).
Особенности, которые необходимо учитывать при работе с надстройкой:
- Все макросы ОБНАРУЖИТЬ, УДАЛИТЬ, ИЗМЕНИТЬ и ИЗВЛЕЧЬ, а также макрос лемматизации манипулируют исходным содержимым ячеек и могут изменить его (что практически всегда происходит), поэтому их нельзя исполнять на исходных данных. Их нужно копировать в отдельный столбец рядом и работать уже с ним.
- Природа всех макросов такова, что они стирают всю историю изменений, поэтому после выполнения макроса пути назад нет. Будьте осторожны ;)
- Еще из особенностей (это касалось и предыдущей версии): макросы работают только с одним столбцом. Если выделить два и более столбца данных, как правило, макрос сработает только на данных из первого столбца. Но может выдать ошибку.
- Надстройка работает в Excel 2010 и позднее, как в 32-битной, так и в 64-битной версии. В Excel 2007 и ранее стабильная работа не гарантируется.
- С Excel for Mac совместимости нет и не будет.
Пробежимся по разделам.
Обнаружить

Все макросы на этой панели возвращают два значения — ИСТИНА или ЛОЖЬ — в зависимости от того, было обнаружено в строке искомое или нет. Ищут, соответственно, латинские буквы, цифры и украинские буквы и сочетания символов.
Удалить

Удаляют из фраз соответствующие элементы. Чтобы не загромождать панель, некоторые пункты собраны в меню, например, слова и символы.
Удаление символов и определенных типов слов нужно при анализе семантического ядра, бывает необходимо избавиться от лишних элементов, чтобы ускорить работу.
Какие символы можно удалить:
- Всю пунктуацию. Этот скрипт использует синтаксис регулярных выражений и поэтому может выполняться сравнительно долго на больших массивах данных (десятки-сотни тысяч строк);
- Лишние пробелы. Этот скрипт использует аналог функции «СЖПРОБЕЛЫ» в VBA и работает довольно шустро на любых объемах;
- Модификаторы у стоп-слов. Это исключительно про контекстную рекламу.
Какие слова можно удалить:
- слова, состоящие из одних цифр;
- стоп-слова;
- повторы слов.
Также в этом разделе остался макрос из предыдущей версии — удаление UTM-меток — и добавлен простенький макрос удаления формул из выделенного диапазона.
Изменить
Макросы преобразования данных. Теперь все операции работы с регистром и операторами соответствия собраны в меню.

В этот раздел добавлены:
-
Исправление заглавных букв у топонимов. Макрос обращается к данным из моего файла, лежащего в Google Документах и доступного по прямой ссылке. Это позволяет вносить в него изменения, не меняя код самой надстройки, и не утяжеляет ее на несколько мегабайт. Дело в том, что, чем легче надстройка, тем быстрее будет загружаться ваш Excel, так как все надстройки загружаются вместе с ним каждый раз при его открытии. Если есть что добавить в список — всегда готов!
-
Функции транслитерации и обратного преобразования.
-
Функция «Инвертировать». Она может понадобиться в тех редких случаях, когда необходимо определить и упорядочить фразы по их окончаниям.
Извлечь
Эти скрипты извлекают данные и возвращают пустоту, если искомое не найдено.

Из совершенно новых:
-
Макрос извлечения прилагательных (определяет и извлекает прилагательные по характерным для них окончаниям). Если хотите посмотреть, какие эпитеты использует ваша целевая аудитория при формировании поискового запроса, и на основе собранной статистики составить тексты или контент сайта — разработка для вас!
-
Длина текста в пикселях. Этот макрос разработан Евгением Юдиным, он помогает определять идеальную длину заголовков, которая позволила бы им обоим уместиться в рекламной выдаче на поиске Яндекса. Рекомендую почитать соответствующий его материал.
-
Извлечение гиперссылок. Макрос добавлен вскоре после написания первой статьи и соответствующие обновления я выкладывал на своей странице в Facebook, но, боюсь, не все об этом узнали.
Другое

Макрос составления частотного словаря и макрос генерации линейных комбинаций списков уже были в прежней версии.
Из новшеств для надстройки:
-
Перенесен из моего знакомого многим файла «Робот-распознаватель» макрос лемматизации по словарю. Это одно из немногих решений в открытом доступе, которое позволяет лемматизировать десятки и сотни тысяч фраз в считанные секунды. К сожалению, словарь лемматизации, как и словарь топонимов, тоже подгружается извне, так как весит 22 МБ и далеко не всегда может быть нужен. Подгружаемые данные открываются в отдельной книге.
-
Макрос «Развернуть кроссминусовку» преобразовывает однострочную минусовку в формате Яндекс.Директа в формат Google AdWords.
-
Макрос «Собрать столбцы» найден где-то в рунете. Замечательный скрипт, который собирает все данные на листе в один столбец в один клик. Иногда бывает очень необходимо.
-
Макрос переноса любого файла выгрузки Директа в формат AdWords, будь то XLS, XLSX или CSV. Вместе с кроссминусовкой на уровне кампаний и ключевых фраз.
Внешние данные
Здесь наиболее интересными станут скрипты сбора данных с бесплатного на текущий момент API Bukvarix, он позволяет собирать семантику по фразе и по домену. Сбор семантики становится прост как никогда.
Также добавлены ссылки на списки гео и тематических категорий AdWords, скачиваемые напрямую с серверов Google. Если у вас есть идеи, что еще добавить в этот раздел из открытых данных — пишите!

Ну и, чтобы не забыть, — ссылки на меня, мой канал, где иногда появляются обучающие видео, и вечная ссылка на папку со всеми инструментами, в которой находится и эта надстройка !SEMTools8.
Пользовательские функции (UDF)
Что такое UDF, описано в предыдущей статье. Функции, которые присутствовали в предыдущей версии, стройным рядом мигрировали в текущую. К ним добавлены некоторые новые. Итоговый список функций теперь таков (x означает ячейка или строковые данные, rng — выбираемый диапазон):
- УдалитьСловаИзСписка(ячейка; список 1 столбец)
- НайтиСловаИзСписка(ячейка; список 2 столбца)
- ЗаменитьСловаИзСписка(ячейка; список 2 столбца)
- УдалитьПовторы(x)
- слов(x)
- ТочноеДиректИлиФразовоеAdWords(x)
- ФразовоеДиректИлиТочноеAdWords(x)
- ЗакрепитьСловоформы(x)
- ТочноеСоСловоформами(x)
- ПроставитьМодификаторы(x)
- SentenceCase(x)
- ЕстьУкраинский(x)
- ЕстьЛатиница(x)
- БезПунктуации(x)
- БезМинусСлов(x)
- ИзвлечьЛатиницу(x)
- ИзвлечьЦифры(x)
- ВсеСБольшой(x)
- ЛатиницаСБольшой(x)
- ГородаСБольшой(x) — капитализация имен собственных (работает только, если подгружен файл словаря, который загружается при вызове макроса «Топонимы»).
- БезUTMметок(x)
- БезСловИзЦифр(x)
- СортироватьАЯВнутриЯчейки(x)
- НайтиАббревиатуры(x)
- Левенштейн(x1; x2) — расстояние Левенштейна между 2 фразами.
- ПохожиеФразы(x1; x2) — Истина или Ложь, в зависимости от того, насколько похожи фразы по чуть дополненному алгоритму подсчета расстояния Левенштейна.
- ДлинаТекстаВПикселях(x; опционально 1 или 0). Второй параметр отвечает за то, хотим мы посмотреть длину жирного или простого текста. Если не использовать параметр, по умолчанию используется вариант жирный.
- ReverseString(x) — строка наоборот.
- Прилагательные(rng) — все прилагательные из строки.
- Translit(x) — транслитерация строки.
- UnTranslit(x) — обратная транслитерация.
- Lemmatize(x) — лемматизация. Работает, если открыт и подгружен файл словаря, подгружается только макросом.
Планы по развитию надстройки
В ближайшее время я планирую:
- реализовать кластеризацию по частотному словарю и по произвольному списку фраз (как в «Роботе-распознавателе»);
- внедрить возможность проверять, появилась ли новая версия у надстройки, и получать ссылки на нее;
- подключить больше открытых полезных для контекстной рекламы данных.






Последние комментарии